【PR】この記事には広告が含まれています。

ラズベリーパイの代表的なオプションパーツであるカメラモジュール。Raspberry Pi財団からオートフォーカス機能が搭載されたカメラモジュール V3が発売されました。
画素数も800万画素から1200万画素になり、HDR(High Dynamic Range)モードも利用できます。性能が大幅にアップしているのにもかかわらず、価格は先代のモデルからあまり変わっていない点も要注目です。
 Camera Module V2 |  Camera Module V3 | |
|---|---|---|
| 画素数 | 800万画素 (3280 × 2464) | 1200万画素 (4608 x 2592) |
| センサー | Sony IMX219 | Sony IMX708 |
| フォーカス | 手動調節式 (固定フォーカス) | モーター駆動 (オートフォーカス) |
| HDR対応 | なし | あり |
| 価格 (KSY) | 4,070円 | 4,620円 |
| 詳細 | 詳細を見る | 詳細を見る |
この記事ではPythonプログラムを使い、カメラモジュールV3を操作する方法を解説します。静止画や動画の撮影から、顔認識や物体認識まで、幅広い活用方法を紹介しています。カメラモジュールV2の操作方法は、以下の記事をご覧ください。
≫【ラズベリーパイ】監視カメラの作り方|PythonでカメラモジュールV2を自在に操作
使用準備

環境の確認
今回、動作確認で使用した環境は以下の通りです。
- Raspberry Pi カメラモジュール V3
- Raspberry Pi 4 Model B
- Raspberry Pi OS (64-bit) Bullseye
OSのバージョンは以下のコマンドで確認できます。
lsb_release -a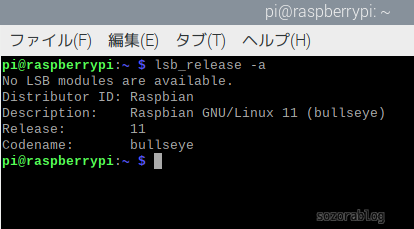
Bullseyeではなく、最新版であるBookwormを使用する場合の注意点を、記事の後半で解説しています。
カメラモジュールの接続
- 黒いロックを持ち上げる。
- リボンケーブルを挿入する
- ロックを下に押し込んで固定する
まず、カメラポートの黒いロック部分を上に持ち上げます。

リボンケーブルを差し込みます。向きに注意してください。端子部分がHDMIポート側に向くよう接続にします。

黒いロック部分を押して固定します。

ライブラリのインストール
Pythonで使う「ライブラリ」とは、便利な機能がたくさん詰まった道具箱のようなものです。これをインストールすると、プログラムを短いコードで簡単に書けるようになります。以下の手順に沿って、必要なライブラリを順番に準備しましょう。
まず、pipを最新のバージョンにします。下記のコマンドをターミナルに入力してEnterキーを押してください。
sudo python -m pip install --upgrade pip
pipを最新にしておくことで、新しい機能やバグ修正が反映され、ライブラリのインストールがスムーズになります。
OpenCVをバージョン指定でインストールします。OpenCVは画像処理に使われるライブラリで、バージョンを指定することで特定の機能を確実に使えるようにします。
sudo pip3 install opencv-python==4.5.1.48数値計算を効率的に行うための「numpy」というライブラリをバージョン指定でインストールします。
sudo pip3 install numpy==1.23.1パッケージリストを最新にします。この操作により、aptでインストールするソフトウェアの情報を最新状態にします。
sudo apt update高速な数値計算をサポートするライブラリで、numpyを効率的に動かすために必要な「libatlas3-base」 パッケージをインストールします。
sudo apt install libatlas3-baseRaspberry Pi 3以前のモデルは追加項目あり
Raspberry Pi 3より以前に発売されたモデルを使用する場合は、追加で設定する項目があります。
- raspi-configの「6 Advanced Options」で「A8 Glamor」を有効にする
- /boot/config.txtで「dtoverlay=vc4-kms-v3d」のコメントアウトを外す
- /boot/config.txtの最下行に「dtoverlay=imx708」を追加
詳細は公式ドキュメントを確認ください。
カメラの動作確認

Raspberry Pi OSには libcamera がインストールされているため、以下のコマンドを使うことでカメラのプレビュー画面を表示できます。
libcamera-hello --timeout 0–timeout オプションに0 を指定すると、プレビューは手動で終了するまでずっと続きます。終了するには Ctrl + C を押してください。
Pythonプログラムで撮影する

まずは基本的な操作方法を解説します。
静止画の撮影(保存)
スタートメニューのプログラミングからThonnyを開きます。
以下のプログラムをコピーペーストします。
from picamera2 import Picamera2
picam2 = Picamera2()
# フル解像度で画像を取得するための設定
capture_config = picam2.create_still_configuration(
main={"size": picam2.camera_properties['PixelArraySize']} # センサーのフル解像度を指定
)
# 設定の適用
picam2.configure(capture_config)
# カメラの開始
picam2.start()
# 画像のキャプチャ
picam2.capture_file("test.jpg")
# カメラの停止
picam2.stop()
プログラムを保存して実行します。
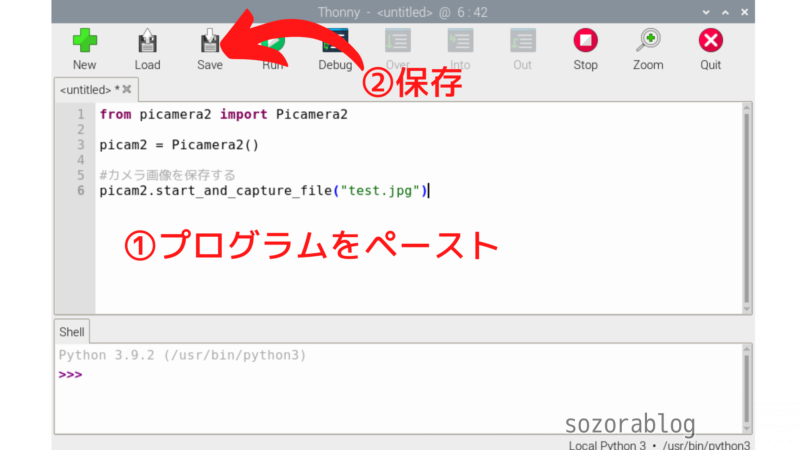
プログラムを実行すると、test.jpgというファイル名で画像が保存されます。
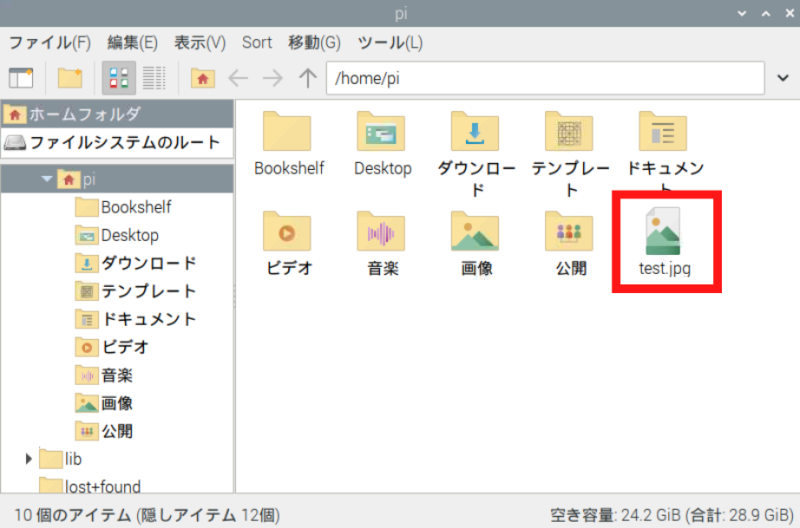
test.jpgという固定のファイル名にすると、撮影するたびに画像が上書きされてしまいます。そこで以下のように撮影した時刻をファイル名にすることで、過去の画像を残しつつ新しい画像を保存できます。
from picamera2 import Picamera2
import datetime
# 現在の日時を取得し、ファイル名に使用する
dt_now = datetime.datetime.now()
file_name = dt_now.strftime('%Y%m%d_%H%M%S')
picam2 = Picamera2()
# フル解像度で画像を取得するための設定
capture_config = picam2.create_still_configuration(
main={"size": picam2.camera_properties['PixelArraySize']} # センサーのフル解像度を指定
)
# 設定の適用
picam2.configure(capture_config)
# カメラの開始
picam2.start()
# 画像のキャプチャ
picam2.capture_file(file_name + '.jpg')
# カメラの停止
picam2.stop()
動画の撮影(保存)
from picamera2 import Picamera2
picam2 = Picamera2()
# 解像度を1920x1080に設定
video_config = picam2.create_video_configuration(
main={"size": (1920, 1080)} # フルHDに変更
)
# 設定の適用
picam2.configure(video_config)
# 動画撮影の開始と5秒後の自動停止
picam2.start_and_record_video("test.mp4", duration=5)
# カメラの停止
picam2.stop()
上のプログラムを実行すると、test.mp4というファイル名で5秒間の動画が保存されます。フル解像度(4608×2592)でのエンコードは、負荷が高くエラーが出たため解像度を1920×1080に下げました。
Pythonプログラムでカメラ映像(動画)を表示する
当初はOpenCVの.read()で画像を読み込もうとしたのですが、映像が表示されませんでした。そこでPicamera2を使って画像を取得してからOpenCVで表示させるという方法にしています。
import cv2
from picamera2 import Picamera2
from libcamera import controls
picam2 = Picamera2()
picam2.configure(picam2.create_preview_configuration(main={"format": 'XRGB8888', "size": (640, 480)}))
picam2.start()
#カメラを連続オートフォーカスモードにする
picam2.set_controls({"AfMode": controls.AfModeEnum.Continuous})
while True:
im = picam2.capture_array()
cv2.imshow("Camera", im)
key = cv2.waitKey(1)
# Escキーを入力されたら画面を閉じる
if key == 27:
break
picam2.stop()
cv2.destroyAllWindows()12行目の「picam2.capture_array()」 は、現在のカメラ映像を NumPy配列として取得する関数です。この配列は画像データを含み、「cv2.imshow()」 でそのまま表示できます。
プログラムを実行するとカメラの映像が立ち上がります。オートフォーカス機能も有効になっているので、近くの映像も鮮明に撮影できます。
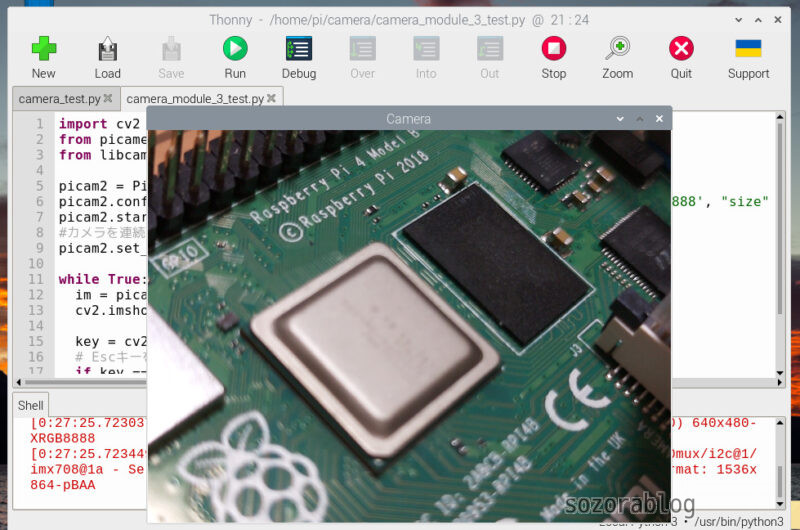
オートフォーカスの速度を早くしたいときは、プログラムの9行目を以下のように変更します。
picam2.set_controls({"AfMode": controls.AfModeEnum.Continuous, "AfSpeed": controls.AfSpeedEnum.Fast})HDR(High Dynamic Range)モードで表示する
HDR(High Dynamic Range)モードにすると、明るい部分と暗い部分がどちらも鮮明に表現できます。明るさの異なる複数枚の画像を合成して、1枚の画像を生成する仕組みです。
本来、HDRをオンにするときはコマンドを入力する必要があります。以下のプログラムではos.systemを使い、プログラム中でHDRをオンにするコマンドを実行しています。
import cv2
from picamera2 import Picamera2
from libcamera import controls
import os
picam2 = Picamera2()
#HDRをオンにする
os.system("v4l2-ctl --set-ctrl wide_dynamic_range=1 -d /dev/v4l-subdev0")
print("Setting HDR to ON")
picam2.configure(picam2.create_preview_configuration(main={"format": 'XRGB8888', "size": (640, 480)}))
picam2.start()
#カメラを連続オートフォーカスモードにする
picam2.set_controls({"AfMode": controls.AfModeEnum.Continuous, "AfSpeed": controls.AfSpeedEnum.Fast})
while True:
im = picam2.capture_array()
cv2.imshow("Camera", im)
key = cv2.waitKey(1)
# Escキーを入力されたら画面を閉じる
if key == 27:
break
picam2.stop()
cv2.destroyAllWindows()
#HDRをオフにする
os.system("v4l2-ctl --set-ctrl wide_dynamic_range=0 -d /dev/v4l-subdev0")
print("Setting HDR to OFF")参考にさせていただいたサイト
How To Use Raspberry Pi Camera Module 3 with Python Code
OpenCVを使用すれば顔認識もできる
OpenCVを使えるメリットは画像を扱うための機能が豊富に用意されていることです。顔認識も以下のような短いコードでかんたんに実装できます。
import cv2
from picamera2 import Picamera2
from libcamera import controls
face_detector = cv2.CascadeClassifier("/usr/local/lib/python3.9/dist-packages/cv2/data/"\
"haarcascade_frontalface_default.xml")
cv2.startWindowThread()
picam2 = Picamera2()
picam2.configure(picam2.create_preview_configuration(main={"format": 'XRGB8888', "size": (640, 480)}))
picam2.start()
#カメラを連続オートフォーカスモードにする
picam2.set_controls({"AfMode": controls.AfModeEnum.Continuous})
while True:
im = picam2.capture_array()
grey = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
faces = face_detector.detectMultiScale(grey, 1.1, 5)
for (x, y, w, h) in faces:
cv2.rectangle(im, (x, y), (x + w, y + h), (0, 255, 0))
cv2.imshow("Camera", im)
key = cv2.waitKey(1)
# Escキーを入力されたら画面を閉じる
if key == 27:
break
picam2.stop()
cv2.destroyAllWindows()映像の中から顔が検出されると、緑の枠で囲まれます。すみません、顔の部分は後から加工して消しています。
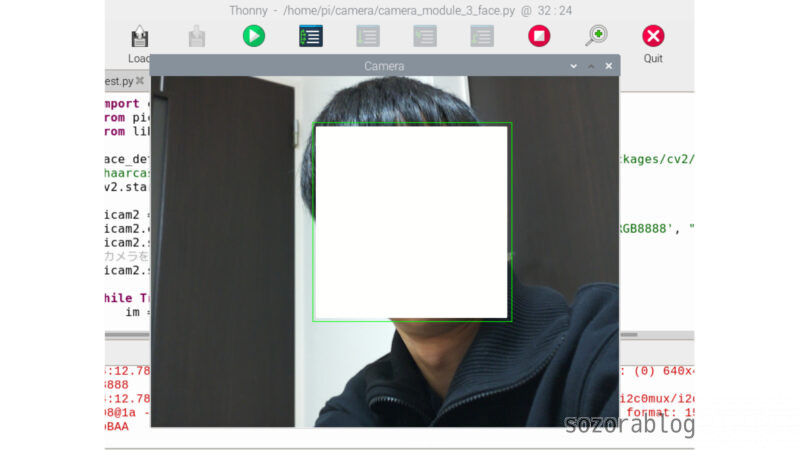
リアルタイム物体認識に挑戦
ここでは顔だけではなく、さまざまな物体を検出する方法を紹介します。Raspberry PiとカメラモジュールV3を使い、MediaPipeを活用した物体検出を試してみましょう。
MediaPipeはGoogleが提供するマルチプラットフォーム対応の機械学習ライブラリで、TensorFlow Lite(軽量版の機械学習ライブラリ)を活用してリアルタイムの映像処理やモデル推論を効率的に行います。
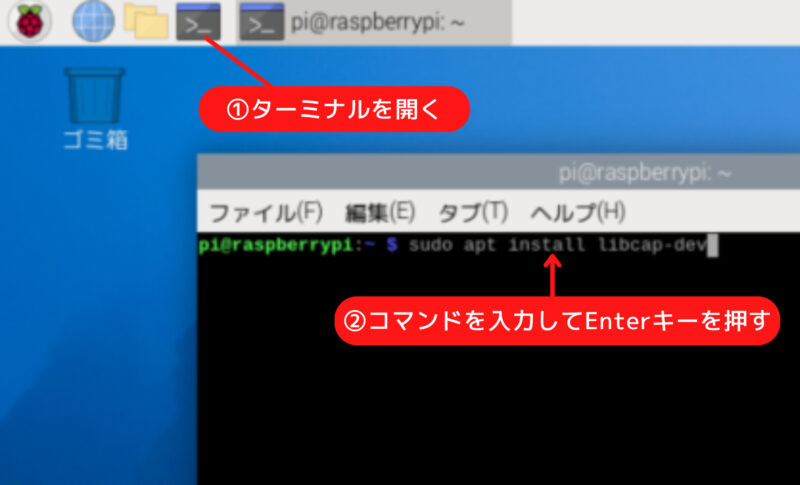
物体認識の環境を作成するには、ターミナルを開き、以下のコマンドを順に実行します。
カメラ制御に必要な libcap ライブラリの開発用ヘッダーをインストールします。
sudo apt install libcap-devMediaPipeのサンプルコード一式をRaspberry Piにコピーします。
git clone https://github.com/googlesamples/mediapipe.gitRaspberry Pi用のオブジェクト検出のサンプルコードがあるディレクトリに移動します。
cd mediapipe/examples/object_detection/raspberry_pi必要な依存パッケージのインストールと環境のセットアップをします。32ビット版のRaspberry Pi OSでは、この段階でエラーが発生する場合があります。この場合は64ビット版の使用を推奨します。
sh setup.sh検出した物体を表示する
以下のコードを、/home/pi/mediapipe/examples/object_detection/raspberry_piに保存します。プログラムの保存場所が異なると、モジュールの読み込み時にエラーが発生するので注意が必要です。
# Copyright 2023 The MediaPipe Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import sys
import time
import cv2
import mediapipe as mp
from picamera2 import Picamera2
from libcamera import controls
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
from utils import visualize
# Initial configuration of the camera
picam2 = Picamera2()
picam2.configure(picam2.create_preview_configuration(
main={"format": 'XRGB8888', "size": (640, 480)}))
picam2.start()
picam2.set_controls({"AfMode": controls.AfModeEnum.Continuous})
# Global variables to calculate FPS
COUNTER, FPS = 0, 0
START_TIME = time.time()
def run(model: str, max_results: int, score_threshold: float,
width: int, height: int) -> None:
global is_inference_in_flight
global latest_detection_result
# Initialize global variables here
is_inference_in_flight = False
latest_detection_result = None
def save_result(result: vision.ObjectDetectorResult,
unused_output_image: mp.Image,
timestamp_ms: int):
"""Callback when the detection is done."""
global is_inference_in_flight, latest_detection_result, COUNTER, START_TIME, FPS
# Mark that inference has finished, so we can send another frame
is_inference_in_flight = False
# Update FPS
if COUNTER % fps_avg_frame_count == 0:
current_time = time.time()
FPS = fps_avg_frame_count / (current_time - START_TIME)
START_TIME = current_time
latest_detection_result = result
COUNTER += 1
# Initialize the object detection model
base_options = python.BaseOptions(model_asset_path=model)
options = vision.ObjectDetectorOptions(
base_options=base_options,
running_mode=vision.RunningMode.LIVE_STREAM,
max_results=max_results,
score_threshold=score_threshold,
result_callback=save_result
)
detector = vision.ObjectDetector.create_from_options(options)
# Visualization parameters
row_size = 50 # pixels
left_margin = 24 # pixels
text_color = (0, 0, 0) # black
font_size = 1
font_thickness = 1
fps_avg_frame_count = 10
# Create a window to display the detection results
cv2.namedWindow('object_detection', cv2.WINDOW_NORMAL)
cv2.resizeWindow('object_detection', 800, 600)
while True:
frame = picam2.capture_array()
if frame is None:
break
# Resize and convert for inference
image = cv2.resize(frame, (width, height))
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=rgb_image)
# If the previous inference is done, start a new one
if not is_inference_in_flight:
detector.detect_async(mp_image, time.time_ns() // 1_000_000)
is_inference_in_flight = True
else:
# If inference is still in flight,
# we do NOT enqueue a new frame to avoid backlog
pass
# Draw FPS
fps_text = 'FPS = {:.1f}'.format(FPS)
text_location = (left_margin, row_size)
cv2.putText(image, fps_text, text_location, cv2.FONT_HERSHEY_DUPLEX,
font_size, text_color, font_thickness, cv2.LINE_AA)
# Visualize the latest detection result (if it exists)
if latest_detection_result is not None:
image = visualize(image, latest_detection_result)
cv2.imshow('object_detection', image)
# Stop if ESC is pressed
if cv2.waitKey(1) == 27:
break
detector.close()
picam2.stop()
cv2.destroyAllWindows()
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--model', help='Path of the object detection model.',
required=False, default='efficientdet.tflite')
parser.add_argument('--maxResults', help='Max number of detection results.',
required=False, default=5)
parser.add_argument('--scoreThreshold',
help='The score threshold of detection results.',
required=False, type=float, default=0.25)
parser.add_argument('--cameraId', help='Id of camera.',
required=False, type=int, default=0)
parser.add_argument('--frameWidth',
help='Width of frame to capture from camera.',
required=False, type=int, default=1280)
parser.add_argument('--frameHeight',
help='Height of frame to capture from camera.',
required=False, type=int, default=720)
args = parser.parse_args()
run(args.model, int(args.maxResults), args.scoreThreshold,
args.frameWidth, args.frameHeight)
if __name__ == '__main__':
main()上記のコードは、Raspberry Piカメラモジュールを使用してリアルタイムで物体検出を行い、検出結果を表示するものです。TFLite(TensorFlow Lite)モデルを使用して物体を検出し、画面上に検出された物体とFPSを描画します。TFLiteは軽量かつ効率的な機械学習モデルを動作させるためのプラットフォームで、Raspberry Piのようなリソースの限られた環境での使用に最適化されています。
このプログラムは、サンプルコードとして提供されているdetect.pyを改良したものです。元のdetect.pyは処理が重く、フリーズしてしまう問題がありました。そこで、「推論中に新しい推論を開始しない」という制御を追加することで、安定した動作を実現しています。
プログラムを実行すると、以下のように表示されます。car、bottle 、cupを検出できました。

検出した物体をカウントする
特定の物体を検出した場合にその数をカウントすることもできます。以下のコードを、/home/pi/mediapipe/examples/object_detection/raspberry_piに保存します。
# Copyright 2023 The MediaPipe Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import sys
import time
import cv2
import mediapipe as mp
from picamera2 import Picamera2
from libcamera import controls
from mediapipe.tasks import python
from mediapipe.tasks.python import vision
from utils import visualize
# 任意の物体名を指定する変数(ここで変更可能)
target_object = "person" # ここを好きな物体名に変更できる
# カメラの初期設定
picam2 = Picamera2()
picam2.configure(picam2.create_preview_configuration(
main={"format": 'XRGB8888', "size": (640, 480)}))
picam2.start()
picam2.set_controls({"AfMode": controls.AfModeEnum.Continuous})
# FPS計算用のグローバル変数
COUNTER, FPS = 0, 0
START_TIME = time.time()
is_inference_in_flight = False
latest_detection_result = None
fps_avg_frame_count = 10
def save_result(result: vision.ObjectDetectorResult,
unused_output_image: mp.Image,
timestamp_ms: int):
"""検出が完了したときに呼び出されるコールバック関数"""
global is_inference_in_flight, latest_detection_result, COUNTER, START_TIME, FPS
# 推論が終了したことをマークし、新しいフレームを送信できるようにする
is_inference_in_flight = False
# 検出結果から指定した物体の数をカウントする
object_count = sum(1 for detection in result.detections if detection.categories[0].category_name == target_object)
# 検出された物体の数をコンソールに出力
print(f"検出された {target_object} の数: {object_count}")
# FPSを更新
if COUNTER % fps_avg_frame_count == 0:
current_time = time.time()
FPS = fps_avg_frame_count / (current_time - START_TIME)
START_TIME = current_time
latest_detection_result = result
COUNTER += 1
# 画像上に検出された物体の数を描画
object_text = f'{target_object.capitalize()}: {object_count}'
image_copy = unused_output_image.numpy_view().copy() # 書き込み可能なコピーを作成
cv2.putText(image_copy, object_text, (24, 100),
cv2.FONT_HERSHEY_DUPLEX, 1, (0, 0, 255), 1, cv2.LINE_AA)
def run(model: str, max_results: int, score_threshold: float,
width: int, height: int) -> None:
global is_inference_in_flight
# オブジェクト検出モデルを初期化
base_options = python.BaseOptions(model_asset_path=model)
options = vision.ObjectDetectorOptions(
base_options=base_options,
running_mode=vision.RunningMode.LIVE_STREAM,
max_results=max_results,
score_threshold=score_threshold,
result_callback=save_result
)
detector = vision.ObjectDetector.create_from_options(options)
# 表示に関するパラメータ
row_size = 50 # ピクセル
left_margin = 24 # ピクセル
text_color = (0, 0, 0) # 黒
font_size = 1
font_thickness = 1
# 検出結果を表示するウィンドウを作成
cv2.namedWindow('object_detection', cv2.WINDOW_NORMAL)
cv2.resizeWindow('object_detection', 800, 600)
while True:
frame = picam2.capture_array()
if frame is None:
break
# フレームをリサイズし、推論用に変換
image = cv2.resize(frame, (width, height))
rgb_image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
mp_image = mp.Image(image_format=mp.ImageFormat.SRGB, data=rgb_image)
# 前回の推論が終了していれば、新しい推論を開始
if not is_inference_in_flight:
detector.detect_async(mp_image, time.time_ns() // 1_000_000)
is_inference_in_flight = True
# FPSを画像上に描画
fps_text = 'FPS = {:.1f}'.format(FPS)
text_location = (left_margin, row_size)
cv2.putText(image, fps_text, text_location, cv2.FONT_HERSHEY_DUPLEX,
font_size, text_color, font_thickness, cv2.LINE_AA)
# 最新の検出結果が存在する場合は画像に描画
if latest_detection_result is not None:
image = visualize(image, latest_detection_result)
# 画像上に検出された物体の数を描画
object_count = sum(1 for detection in latest_detection_result.detections if detection.categories[0].category_name == target_object)
object_text = f'{target_object.capitalize()}: {object_count}'
cv2.putText(image, object_text, (24, 100), cv2.FONT_HERSHEY_DUPLEX,
font_size, text_color, font_thickness, cv2.LINE_AA)
cv2.imshow('object_detection', image)
# ESCキーが押されたら終了
if cv2.waitKey(1) == 27:
break
detector.close()
picam2.stop()
cv2.destroyAllWindows()
def main():
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument('--model', help='オブジェクト検出モデルのパス',
required=False, default='efficientdet.tflite')
parser.add_argument('--maxResults', help='検出結果の最大数',
required=False, default=5)
parser.add_argument('--scoreThreshold',
help='検出結果のスコア閾値',
required=False, type=float, default=0.25)
parser.add_argument('--cameraId', help='カメラID',
required=False, type=int, default=0)
parser.add_argument('--frameWidth',
help='カメラからキャプチャするフレームの幅',
required=False, type=int, default=1280)
parser.add_argument('--frameHeight',
help='カメラからキャプチャするフレームの高さ',
required=False, type=int, default=720)
args = parser.parse_args()
run(args.model, int(args.maxResults), args.scoreThreshold,
args.frameWidth, args.frameHeight)
if __name__ == '__main__':
main()
このコードはRaspberry Piに接続されたカメラを使い、リアルタイムで指定した物体を認識し、その数をカウントして画面に表示するものです。
26行目のtarget_objectという変数にはカウントしたい物体の名前を指定します。初期値は”person”となっていますが、ここを変更することで”car”や”bottle”など、別の物体をカウントできます。
物体が検出されると、save_resultという関数が呼び出されます。この関数では、検出された物体の中から、target_objectで指定した物体をカウントします。
以下はtarget_objectに「car」を指定してプログラムを実行した際の結果です。画面の左上に「Cars: 5」と表示されています。ミニカーですが、5台しっかりとカウントできています。

Bookwormを使用する場合

Raspberry Pi OSの最新版であるBookwormを使用する場合は、基本的にBullseye(Legacy)版と同じコードでカメラを操作できます。ただし、仮想環境の作成が必要である点に注意が必要です。
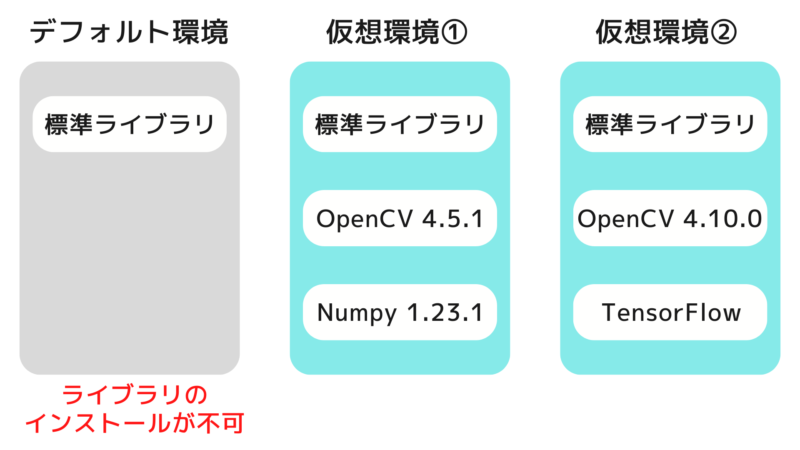
仮想環境とは、Pythonの実行環境をプロジェクトごとに独立して管理できる仕組みです。これにより、ライブラリ同士のバージョンによる競合を防ぎ、予期せぬエラーを回避できます。
Bookwormでは仮想環境を使用せずにpipを実行するとエラーが発生し、ライブラリをインストールできない仕様になっています。
ライブラリのインストール
まず、パッケージリストを最新にします。
sudo apt updateカメラ制御に必要な libcap ライブラリの開発用ヘッダーをインストールします。
sudo apt install libcap-devここまでは仮想環境内ではなく、システム全体に対して実行します。apt installは、システム全体に対してパッケージをインストールするコマンドだからです。
次からはPythonライブラリをインストールするため仮想環境を作成します。my_envは仮想環境の名前です。好きな名前に変更して構いません。
python3 -m venv my_env --system-site-packages/home/piを開くと、my_envというフォルダが作成されています。このフォルダ内には、ライブラリをインストールするためのディレクトリが含まれています。
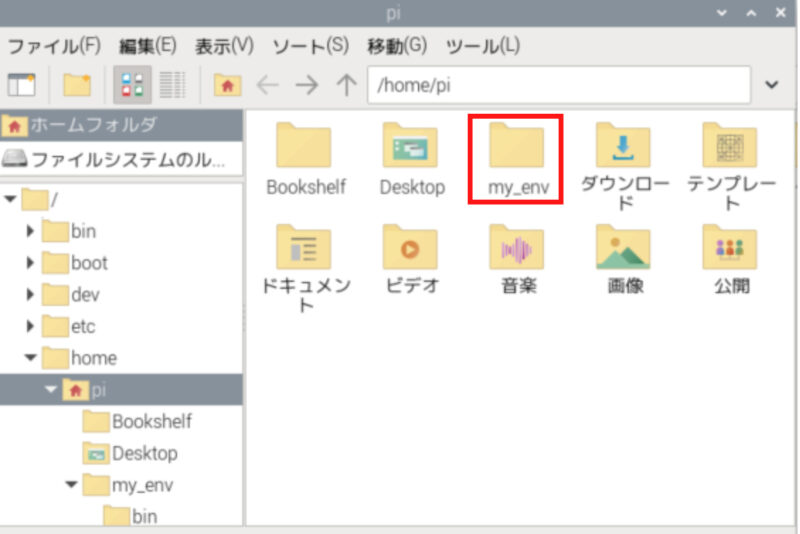
作成した仮想環境を有効にします。
source my_env/bin/activateターミナルのプロンプト(コマンドラインの先頭)が次のように変わります。(my_env) という表示は、仮想環境が有効になっていることを示しています。
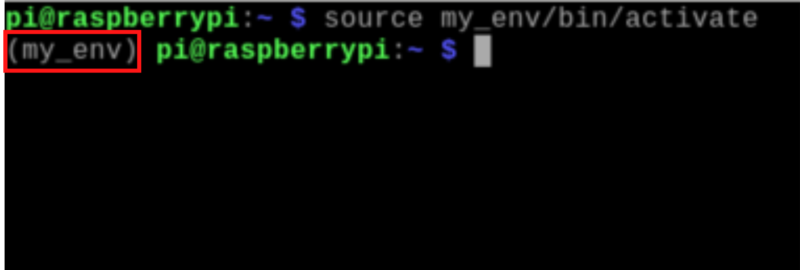
この状態でライブラリをインストールすると、仮想環境内にのみ影響します。また、Pythonスクリプトを実行しても、仮想環境に限定された環境で動作します。
仮想環境内で、pipを最新バージョンにアップグレードします。
pip install --upgrade pipOpenCVを指定したバージョンでインストールします。
pip install opencv-python==4.10.0.84仮想環境でプログラムを実行
Thonnyからプログラムを実行する場合、そのまま実行するとシステム全体のPython環境を使用してしまいます。これを避けて仮想環境を使用するには、以下の手順を行います。
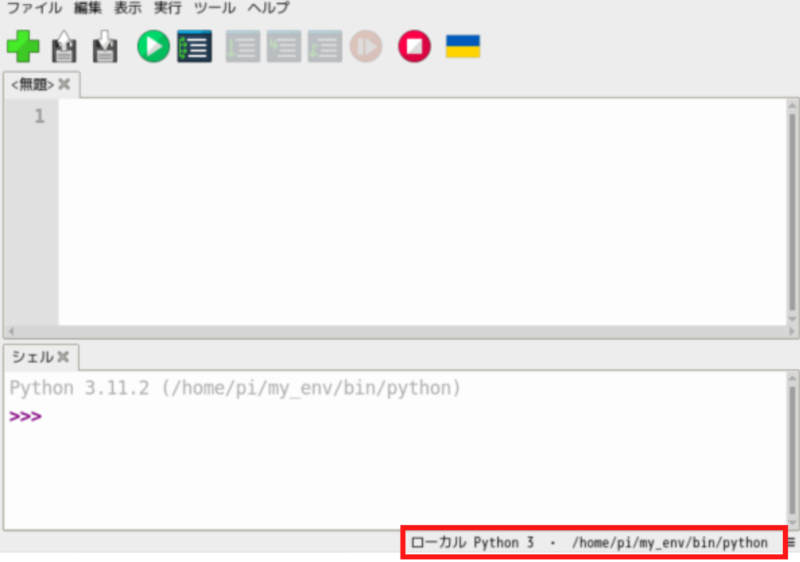
Thonnyの画面右下部分をクリックします。
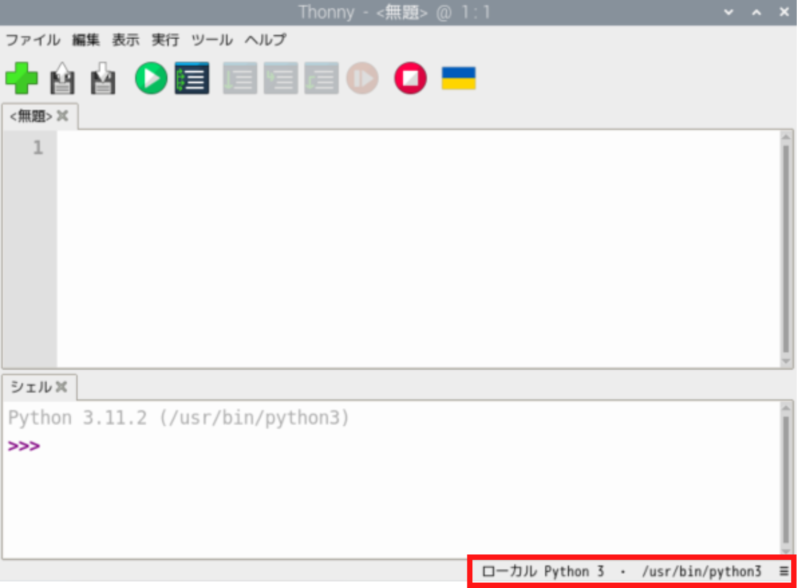
「インタプリタ設定」をクリック。
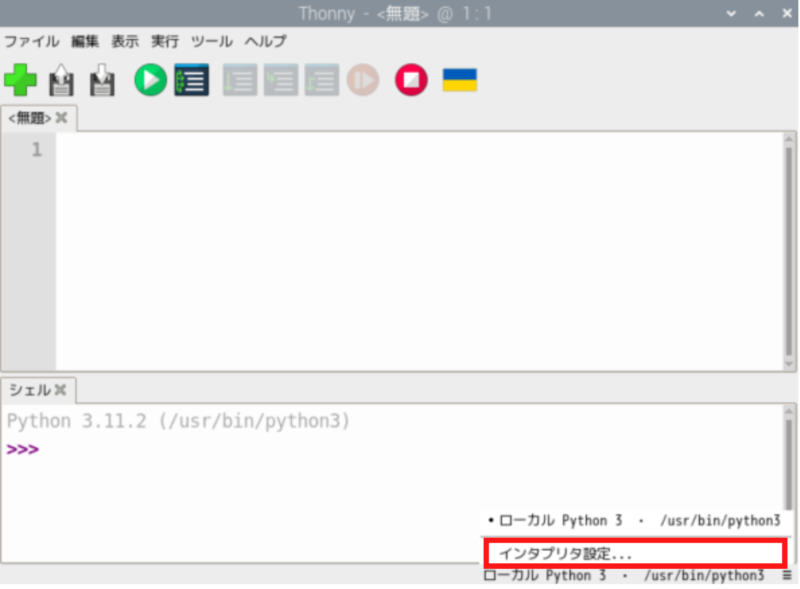
「…」のボタンをクリック。
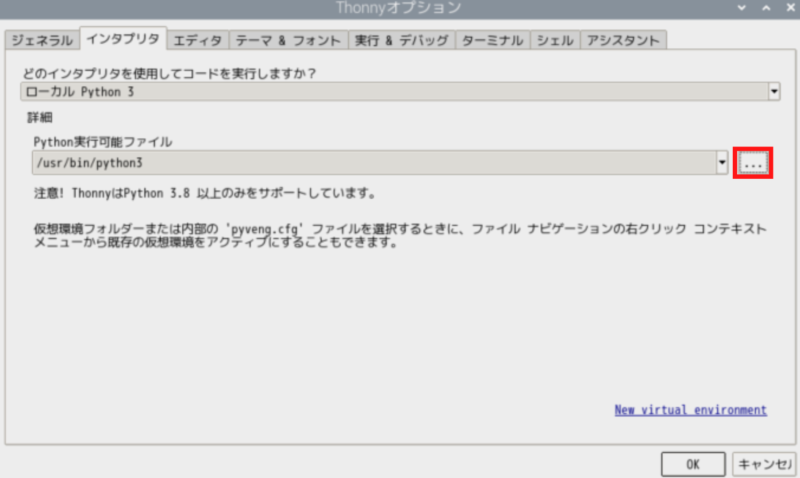
先ほど作成した仮想環境のディレクトリを開き、binフォルダ内のpythonを選択します。
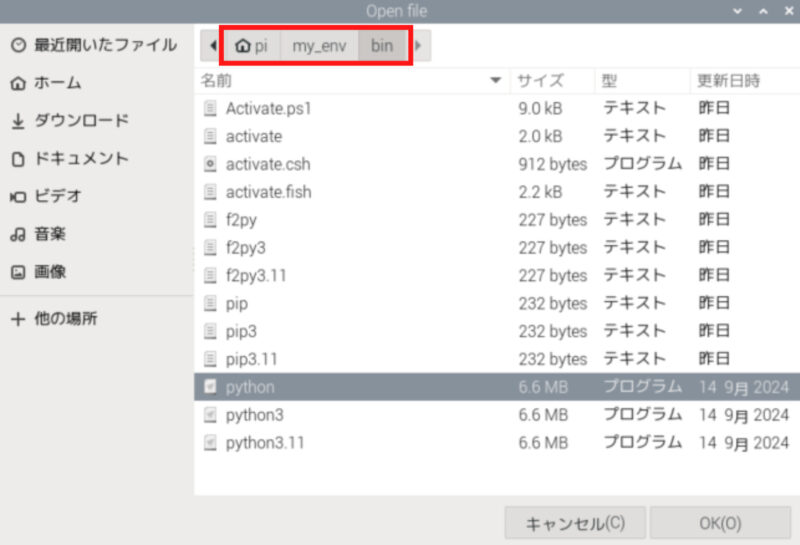
「OK」をクリックします。
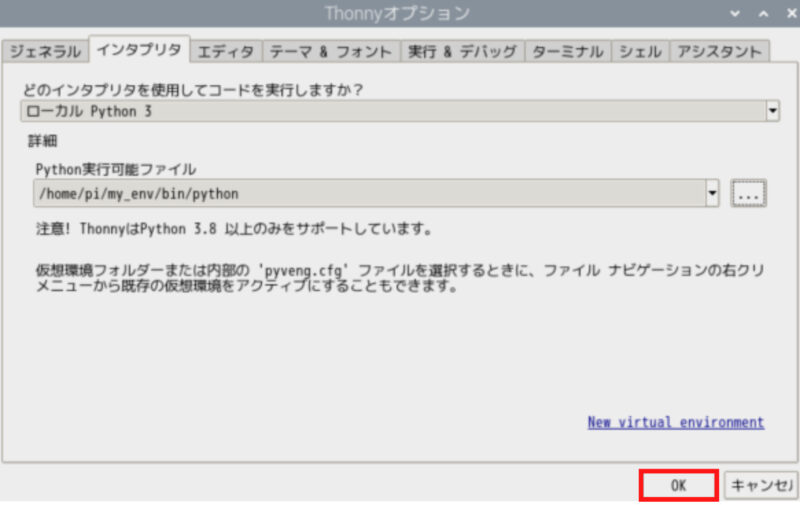
プログラムの実行環境が仮想環境に切り替わりました。
コメント一覧
返信ありがとうございます!
こちらの問題は解決しました!ありがとうございます!
続いて恐縮なのですが、同じプログラムを実行した際に出るこれらのエラーはどうしたらいいのでしょうか?
ImportError: libopenblas.so.0: cannot open shared object file: No such file or directory
During handling of the above exception, another exception occurred:
raise ImportError(msg)
ImportError:
IMPORTANT: PLEASE READ THIS FOR ADVICE ON HOW TO SOLVE THIS ISSUE!
Importing the numpy C-extensions failed. This error can happen for
many reasons, often due to issues with your setup or how NumPy was
installed.
NumPyが依存しているlibopenblas.so.0というライブラリが見つからないことが原因でNumPyが正しく動作していない可能性があります。
以下のコマンドを実行してみてください。
sudo apt update
sudo apt install libopenblas-dev
NumPy自体も再インストールが必要かもしれません。
pip install –upgrade –force-reinstall numpy
よろしくお願いいたします。
コメント失礼します。
現在のnumpy(2.0.2)ではエラーが起こるため、最新のものではダメとのことです。
色々試した所、そぞらさんの監視カメラの記事から1.23.1のものでなら動作確認が取れました!
以上、linux初心者からの報告です…笑
コメント失礼します。
いつもそぞらさんのブログを参考にさせていただいております、ぐらと申します。
こちらのサイトに書かれていた、カメラモジュールv3を使った動作は全て正常に動きました。ありがとうございます。
質問なのですが、静止画や動画を撮った際に同じ名前で保存すると、最新に撮ったものしか表示されません。そぞらさんが書かれた以下サイトにその対処法が書かれていたのですが、カメラモジュールv3でも同じプログラムを使っても良いのでしょうか?
https://sozorablog.com/camera_shooting/
なお、使用しているものは以下のとおりです。
Raspberry-Pi v4(OS:Bullseye)
Python v3.9.4
カメラモジュール v3 Noir
ブログを読んでいただいてありがとうございます。
カメラモジュールV3の場合はcv2でカメラ映像を保存することができません。
以下のように、Picamera2で保存してみて下さい。
from picamera2 import Picamera2
import datetime
# 現在の日時を取得し、ファイル名に使用する
dt_now = datetime.datetime.now()
file_name = dt_now.strftime(‘%Y%m%d_%H%M%S’)
picam2 = Picamera2()
# カメラ画像を保存する
picam2.start_and_capture_file(file_name + ‘.jpg’)
返信ありがとうございます。
提示していただいたプログラムを実行したところ、エラーが出ましたが、
(“%Y%m%d_%H%M%S”)と(file_name + “.jpg”)に訂正したところ、無事起動しました。
また、動画撮影の方も頂いたプログラムを参考に設定したところ、名前別で保存することができました。
ありがとうございました。
先週発売開始されたSONYのAIセンサー付きのRaspberry Pi AI Cameraのレビューをお願いします!
コメントありがとうございます。
残念ながら、AI Cameraは初回ロットを買いそびれてしまいました。
また入手したらレビューしたいと思います。
コメント失礼いたします。
Raspberry Pi v4とRaspberry Piカメラモジュールv3を用いて実験を行っています。
夜の鹿を検出したく、パソコンでYOLOv5を用いて学習データを作成しました。このデータをraspberry piに移し、鹿が検出されたときに写真を撮るようにした以下プログラムを行ったところ、カメラが見つからないというエラーが表示されました。chatgptにも聞いたのですが、提示された問題は全て問題ありませんでした。
もちろん物理的なつなぎも問題なく、手つまりの状態です。
そこで、行うプログラムを改良しようと思うのですが、そぞらさんはどこが問題だと思われますか?
import torch
import time
from PIL import Image
import numpy as np
import cv2
from picamera2 import Picamera2
from picamera2 import Preview
# YOLOv5のモデルをロード(必要なモデルを指定)
model = torch.hub.load(‘ultralytics/yolov5’, ‘custom’, path=’best.pt’) # 学習済みモデルのパスを指定
# カメラモジュールの初期化
picam2 = Picamera2()
picam2.start_preview(Preview.NULL)
picam2.start()
while True:
# カメラからフレームを取得
frame = picam2.capture_array()
if frame is None:
print(“フレームの読み込みに失敗しました”)
break
# フレームをRGBに変換
frame_rgb = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
# YOLOv5で推論を実行
results = model(frame_rgb) # フレームを入力としてモデルに渡す
# 検出結果を取得
detections = results.xywh[0].cpu().numpy() # (x_center, y_center, width, height, confidence, class_id)
# 検出結果の処理
for detection in detections:
x_center, y_center, width, height, confidence, class_id = detection
# クラスIDに基づき鹿を検出
if class_id == 0: # 鹿のクラスIDが0だと仮定
if confidence > 0.5: # 信頼度が50%以上の場合に検出
# バウンディングボックスを描画
x1 = int((x_center – width / 2) * frame.shape[1])
y1 = int((y_center – height / 2) * frame.shape[0])
x2 = int((x_center + width / 2) * frame.shape[1])
y2 = int((y_center + height / 2) * frame.shape[0])
# バウンディングボックスを描画
cv2.rectangle(frame, (x1, y1), (x2, y2), (255, 0, 0), 2)
cv2.putText(frame, f'{confidence:.2f}’, (x1, y1-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
# 写真を撮る処理
timestamp = time.strftime(‘%Y%m%d_%H%M%S’)
filename = f’deer_{timestamp}.jpg’
Image.fromarray(frame).save(filename) # 写真を保存
print(f”鹿を検出しました: {filename}”)
# フレームを表示(オプション)
cv2.imshow(“Frame”, frame)
# ‘q’キーで終了
if cv2.waitKey(1) & 0xFF == ord(‘q’):
break
# リソースを解放
picam2.stop()
cv2.destroyAllWindows()
以下は、出たエラーです。
File “/usr/lib/python3/dist-packages/picamera2/picamera2.py”, line 406, in _initialize_camera
raise RuntimeError(“Camera(s) not found (Do not forget to disable legacy camera with raspi-config).”)
RuntimeError: Camera(s) not found (Do not forget to disable legacy camera with raspi-config).
During handling of the above exception, another exception occurred:
File “/usr/lib/python3/dist-packages/picamera2/picamera2.py”, line 254, in __init__
raise RuntimeError(“Camera __init__ sequence did not complete.”)
RuntimeError: Camera __init__ sequence did not complete.
エラーを見ると、「カメラが見つかりません(raspi-config でレガシーカメラを無効にするのを忘れないでください)」
と出ています。
Raspberry Pi の設定で「レガシーカメラ」が有効になっていないかを確認してみてください。
sudo raspi-configで設定できます。
それでもできない場合は、「libcamera-hello –timeout 0」のコマンドを実行してカメラ映像が出るか確認してみてください。
こんばんは
ラズパイ用カメラ
ラズテック製のラズパイ用カメラモジュール
ov5674センサー
を使用しております
CV2のコマンドで
cap_prop_fpsを実行したとき-1が返されてFPS取得ができません。
原因がわからないのですがもしご存知でしたら
原因と対応策ご教授いただきたいです。
よろしくお願いします。
ov5674センサーを使ったことがないので正確な回答ができないかもしれませんが
おそらく、libcameraベースのドライバを使用しているため、OpenCV の VideoCapture が使えないことが原因かと思います。
カメラの設定上のFPSを知りたい場合は、ターミナルで以下のコマンドを実行してみてください。
libcamera-hello –list-cameras
また、実際のFPSを確認するには、フレームごとの処理時間を計測してFPSを算出する方法もあります。
from picamera2 import Picamera2
picam2 = Picamera2()
#カメラ画像を保存する
picam2.start_and_capture_file(“test.jpg”)
を実行すると
Camera(s) not found (Do not forget to disable legacy camera with raspi-config).Camera __init__ sequence did not complete.
とエラーが出てしまいます。
これはどう解決したらよろしいでしょうか?
お問い合わせありがとうございます。
エラー内容を見ると、legacy cameraが有効になっている可能性が考えられます。
ターミナルで以下のコマンドを入力してraspi-configを開きます。
sudo raspi-config
メインメニューから「3 Interface Options」(インターフェイスオプション)を選択します。
インターフェイスオプションメニューから「I1 Legacy Camera」(レガシーカメラ)を選択します。
「いいえ」(無効)を選択して、レガシーカメラインターフェースを無効にします。
設定を完了した後、指示に従ってRaspberry Piを再起動します。これにより、変更が有効になります。
これで、エラーが解決しない場合は、使用しているカメラの製品名とRaspberry Piのモデル名を教えてください。
よろしくお願いいたします。