【PR】この記事には広告が含まれています。

PiSugarから音声と表示を一体で扱える拡張ボード「Whisplay HAT」が登場しました。Raspberry Piに差し込むだけで、マイクとスピーカーによる音声入出力、LCD表示、ボタン操作までをまとめて利用できます。

今までになかったコンセプトの製品で、昨今のAIブームとも相性が良く、音声インターフェースを使ったガジェットを手軽に作れる点が魅力です。
この記事では、Whisplay HATを使い、AIチャットボットとニュース読み上げガジェットの作り方を解説します。ラズパイの可能性がさらに広がる感覚をつかめるはずです。
私が購入した時点では、Amazonで在庫がなく、公式サイトから購入しました。
Whisplay HATは音声アシスタントに特化

Whisplay HATは、Raspberry Pi Zero 2 WやRaspberry Pi 5に対応した、音声と表示をまとめて扱える拡張ボードです。Raspberry Piに取り付けることで、以下の機能が使えるようになります。
- 音声の入出力(マイク・スピーカー)
- LCD画面の表示
- ボタン入力の取得
- RGB LEDの制御

Raspberry PiのGPIOにそのまま差し込むだけで利用できる便利な設計です。複雑な配線を行う手間がなく、使い始められます。

Raspberry Pi Zero 2 Wと同サイズなので、一体感のあるスマートな見た目に仕上がる点が気に入っています。
Whisplay HATの使用準備

Raspberry Pi OSはTrixieのデスクトップ版を選択しました。
Whisplay HATの取り付け

Raspberry PiのGPIOピンに差し込みます。この際、LCD部分を押さえないように注意しましょう。
Whisplay HATの初期設定
Raspberry Piを起動して、Whisplay HATの使用準備をします。
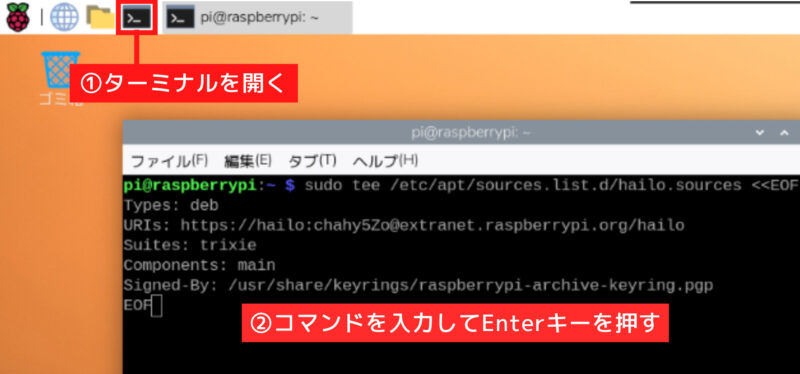
Whisplay HATのプログラムをダウンロードします。--depth 1は最新版だけを取得する指定です。以下を入力したあとにEnterキーを押すと実行されます。
git clone https://github.com/PiSugar/Whisplay.git --depth 1フォルダを移動します。
cd Whisplay/Driver以下を実行すると、音声チップの設定や、I2C・I2Sといった通信機能の有効化が自動で行われます。先頭のyesは、途中で表示される確認メッセージに対して自動的に「yes」と答えるためのものです。
yes | sudo bash install_wm8960_drive.shRaspberry Piを再起動して、設定を反映させます。
sudo rebootWhisplay HATの動作確認
再起動したら、Whisplay HATの動作を確認するためのテストプログラムを実行してみましょう。以下のコマンドでtest.pyを起動します。
cd /home/pi/Whisplay/example && python3 test.py
プログラムを起動すると、data/test.pngの画像がLCDに表示されます。Whisplay HATの右側面に付いている白いボタンを押すと、サンプルの音声が再生され、画面とLEDの色が赤・緑・青の順に切り替わります。

この動作により、画面表示、音声再生、LED制御、ボタン入力といった機能が正常に動いているかを確認できます。テストコードの中身を確認することで、Whisplay HATの動かし方が理解でき、オリジナルのプロジェクトを作る際のヒントにもなります。
音量の調整
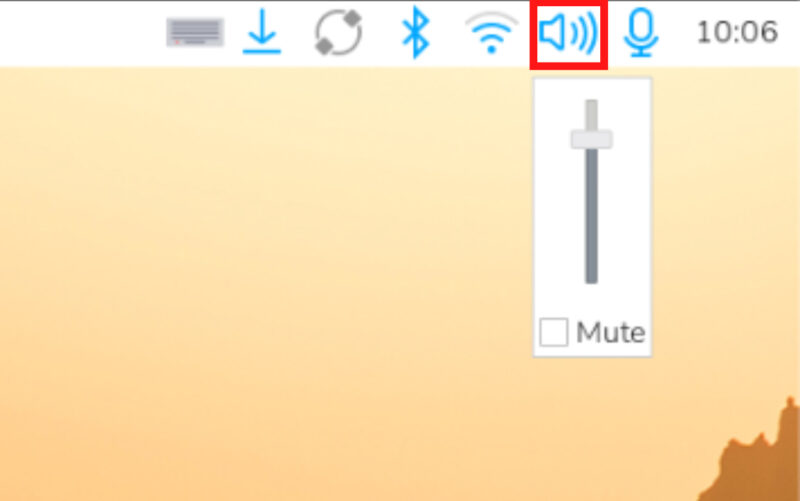
スピーカーの音量は、デスクトップ画面右上のスピーカーのアイコンをクリックして変更できます。
AIチャットボットを動かす

メーカーが公開している音声チャットボット「Whisplay AI Chatbot」を使うことで、会話デバイスを簡単に構築できます。ボタンを押して話しかけると、AIが音声で返答する仕組みです。
Whisplay AI Chatbotは、複数のAIサービスに対応しています。クラウド型ではOpenAIやGeminiなどが使えます。ローカル型ではOllamaやWhisper、Piperなどを使ってオフライン動作も可能です。

ここでは、最も簡単に設定できるOpenAIのサービスを使って設定します。
まずはGitHubに公開されているソースコード(プログラム一式)をダウンロードします。whisplay-ai-chatbotフォルダが作成され、その中にソースコードが保存されます。
git clone https://github.com/PiSugar/whisplay-ai-chatbot.gitダウンロードしたフォルダへ移動します。
cd whisplay-ai-chatbotプログラムを動かすために必要なソフトをまとめてインストールします。以下を実行すると、音声処理やAIの動作に必要なライブラリ、Node.jsやPython関連のパッケージが自動でインストールされます。
bash install_dependencies.sh設定ファイル(.bashrc)の内容を反映します。
source ~/.bashrc.env.templateをコピーして.envというファイルを作成します。
cp .env.template .envチャットボットは、設定が書かれた.envというファイルを読み込んで動きます。
次のコマンドで.envを開きます。nanoはターミナル上でテキストファイルを編集できるシンプルなエディタです。
nano .envAPIキーを準備する
ここでは詳細を説明しませんが、以下の手順でOpenAIのAPIキーを作成します。事前にAPI利用料金も確認しておきましょう。使用するモデルはデフォルトでgpt-4oが設定されています。
- 管理画面(APIプラットフォーム)を開く
- アカウントを作成またはログインする
- 金額を選んでクレジットを購入($5 creditsで十分)
- OpenAI developer platformの画面右上の歯車マークをクリック
- 「API keys」ページに移動する
- 「Create new secret key」をクリックしてAPIキーを発行する
- 表示されたキーをコピーして保存する
APIキーを設定する
テンプレートはデフォルトで音声認識・会話処理・音声出力のすべてをOpenAIで行う設定になっています。.envの下の方までスクロールして、OpenAIのAPIキーを入力します。
OPENAI_API_KEY=ここに自分のAPIキー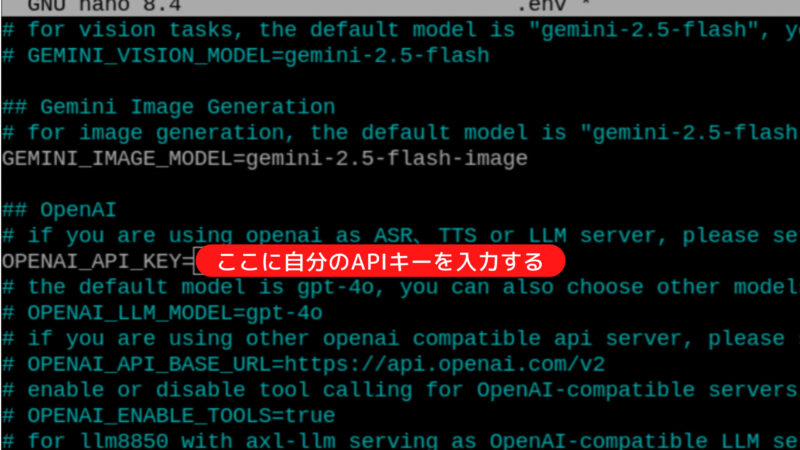
nano .envで編集したあと、Ctrlキーを押しながらOを押して保存します。画面下にファイル名が表示されるので、そのままEnterキーを押すと保存が確定します。その後、Ctrlキーを押しながらXを押すとnanoが終了します。
プロジェクトをビルドします。依存パッケージの準備や必要なファイルの生成が行われ、チャットボットを起動できる状態になります。
bash build.shチャットボットを動かしてみる
以下のコマンドでチャットボットが起動します。
bash run_chatbot.sh
起動後は、Whisplay HATの右側面に付いている白いボタンを押している間に話しかけます。話し終えたらボタンを離すと、音声がOpenAIに送信され、内容が解析されます。

その後、AIが返答を生成し、その内容が音声として再生されます。

終了する場合は、ターミナルでCtrlキーとCを押すと停止します。
Raspberry Piを再起動したあとは、以下のコマンドでチャットボットを起動できます。
cd ~/whisplay-ai-chatbot && bash run_chatbot.shニュースを読み上げるガジェットを作ろう

ここからはWhisplay HATの独自の使い方を紹介します。API料金を気にせず使える方法として、ローカル環境だけで音声を生成する構成を考えました。今回はインターネットからニュースを取得し、その見出しを音声で読み上げるガジェットを作成します。
テキストをしゃべらせてみよう
OpenJTalkをインストールします。OpenJTalkは、名古屋工業大学を中心に開発された、日本語の文章を音声に変換して読み上げるオープンソースの音声合成エンジンです。
sudo apt install -y open-jtalk open-jtalk-mecab-naist-jdic hts-voice-nitech-jp-atr503-m001Open JTalkで日本語を正しく音声合成するための辞書と基本音声モデルをインストールします。
sudo apt install -y open-jtalk-mecab-naist-jdic hts-voice-nitech-jp-atr503-m001音声対話ソフトMMDAgentのサンプルに含まれる音声を取得します。
wget https://downloads.sourceforge.net/project/mmdagent/MMDAgent_Example/MMDAgent_Example-1.8/MMDAgent_Example-1.8.zipZIP形式のファイル「MMDAgent_Example-1.8.zip」を解凍します。
unzip MMDAgent_Example-1.8.zipmeiフォルダをシステムの音声データ用ディレクトリ(/usr/share/hts-voice/)にコピーします。
sudo cp -r MMDAgent_Example-1.8/Voice/mei /usr/share/hts-voice/Thonnyを開いて、Pythonのプログラムを実行します。
以下のコードをコピーペーストして実行してみましょう。Whisplay HATのスピーカーから「こんにちは」の音声が流れるはずです。
import subprocess
def speak_japanese(text, voice="normal", speed=0.8):
# voiceで選択できる種類
# "normal" : 標準
# "happy" : 明るい
# "angry" : 怒り
# "sad" : 悲しい
# "bashful" : 照れ
voice_path = f"/usr/share/hts-voice/mei/mei_{voice}.htsvoice"
subprocess.run(
[
"open_jtalk",
"-x", "/var/lib/mecab/dic/open-jtalk/naist-jdic",
"-m", voice_path,
"-r", str(speed),
"-ow", "/tmp/test.wav"
],
input=text,
text=True
)
subprocess.run(["aplay", "/tmp/test.wav"])
speak_japanese("こんにちは", "happy")日本語テキストをOpenJTalkで音声に変換し、/tmp/test.wavに保存してから再生する処理です。読み上げる内容はtextに入れた文字で決まり、voiceで声の種類(normal・happyなど)を選べます。speedで話す速さを調整でき、数値が小さいほどゆっくり、大きいほど速くなります。
最後のspeak_japanese("こんにちは", "happy")は、「こんにちは」を明るい声で再生する指定です。
ニュースを取得してみよう
NHKのRSSを使い、ニュースの見出しを取得する手順を確認します。RSSはニュースサイトが更新情報を公開している仕組みで、その中に含まれる見出しデータを読み取ることでニュースの見出しを取得できます。
仮想環境を作成
python3 -m venv venv --system-site-packages仮想環境を有効化
source venv/bin/activateRSSはXML形式なので、解析用ライブラリをインストールします。
pip install feedparserThonnyを仮想環境に切り替える
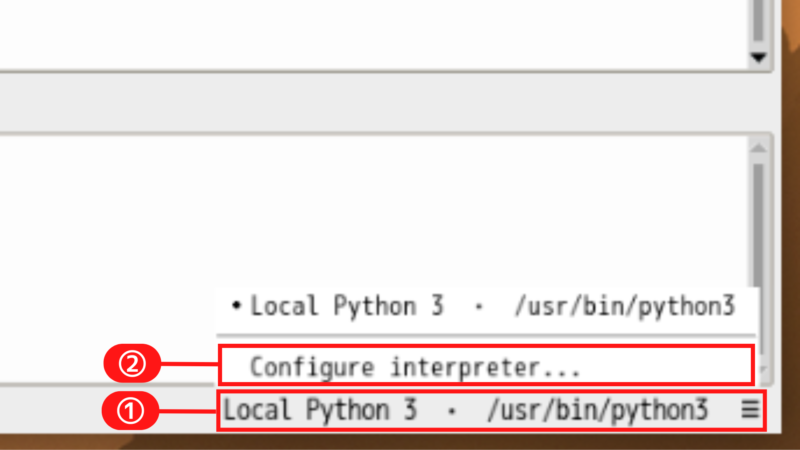
「Python executable」の右側にある「…」ボタンをクリックして、使用するPython(仮想環境のpython)を選択します。
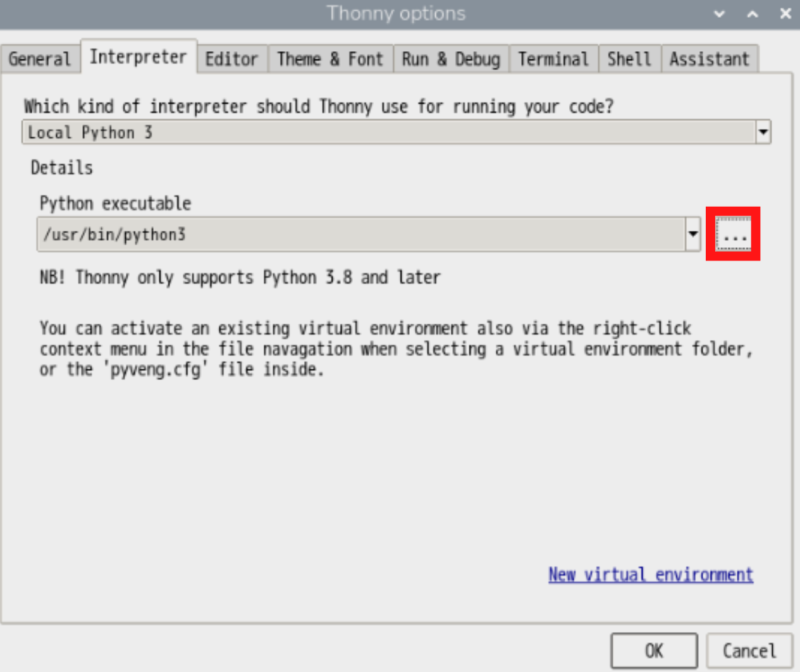
ホームをクリック。
venvを選択
binを選択。
pythonを選択。
OKをクリック。
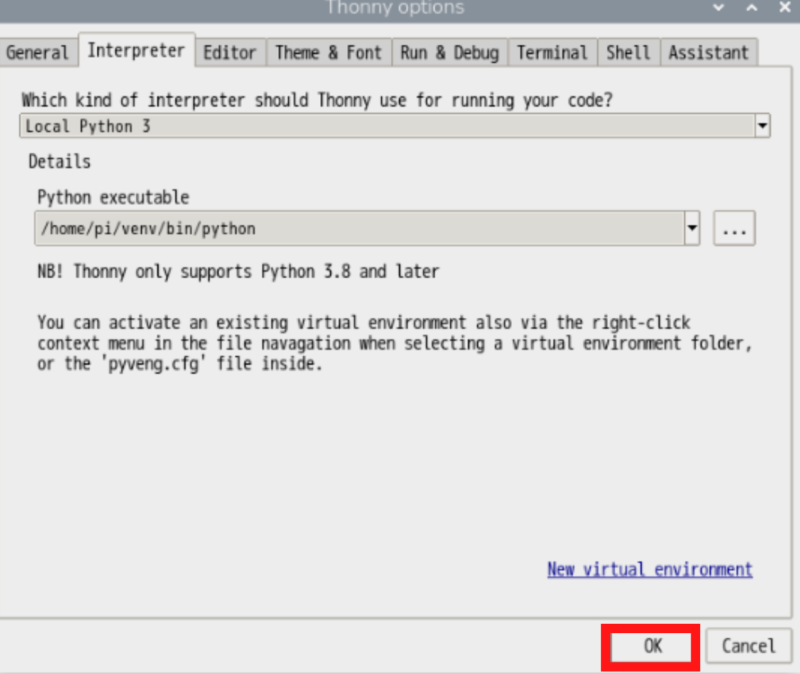
仮想環境に切り替えたら、Thonnyで以下を実行します。
import feedparser
url = "https://www.nhk.or.jp/rss/news/cat0.xml"
feed = feedparser.parse(url)
for entry in feed.entries[:5]:
print(entry.title)このコードは、インターネット上のニュースを取得して表示するプログラムです。まず、NHKが公開しているRSSのURLからニュース情報を読み込みます。URLに含まれるcat0はニュースのカテゴリを表しており、主要ニュース(総合)の見出しを取得できます。この数値を変更すれば、さまざまなジャンルのニュースに切り替え可能です。
| cat番号 | ジャンル |
| cat0 | 主要ニュース |
| cat1 | 社会 |
| cat2 | 文化・エンタメ |
| cat3 | 科学・医療 |
| cat4 | 政治 |
| cat5 | 経済 |
| cat6 | 国際 |
| cat7 | スポーツ |
eedparser.parse(url)でデータを取得すると、その中にニュースの一覧が含まれます。feed.entriesには記事ごとの情報が入っており、[:5]とすることで最初の5件だけを取り出しています。
動画とアイコンを準備する
ニュースの取得方法がわかったら、画面表示の準備をします。ニュースの文字を表示するだけでは味気ないので、アイコンと背景動画で気分を盛り上げることにしました。
映画マトリックス風の動画は、Pixabayで公開されているものをダウンロードして使用します。Pixabayは著作権フリーの画像、動画、音声などを共有するサイトです。サイズは640×360のものをダウンロードしました。
スピーカーのアイコン画像は以下からダウンロードできます。私がCanvaで作成したものです。
動画とアイコンはRaspberry Piの「/home/pi」ディレクトリに保存します。動画のファイル名はmatrix.mp4に必ず変更してください。スクリプトから参照できなくなります。
Pythonで画像や映像を扱えるOpenCVライブラリをインストールします。
sudo apt install -y python3-opencv完成したプログラム
以下はWhisplay HATを使い、RSSから取得したニュースを音声で読み上げながらテキスト表示するプログラムです。
import cv2
import time
import sys
import os
import numpy as np
from PIL import Image, ImageDraw, ImageFont
import subprocess
import feedparser
import unicodedata
import threading
mode = 0
speech_ready = False
sys.path.append(os.path.abspath("/home/pi/Whisplay/Driver"))
from WhisPlay import WhisPlayBoard
# =========================
# TTS
# =========================
def speak(text, voice="normal", speed=0.9):
voice_path = f"/usr/share/hts-voice/mei/mei_{voice}.htsvoice"
subprocess.run(
[
"open_jtalk",
"-x", "/var/lib/mecab/dic/open-jtalk/naist-jdic",
"-m", voice_path,
"-r", str(speed),
"-ow", "/tmp/test.wav"
],
input=text,
text=True
)
subprocess.run(["aplay", "/tmp/test.wav"])
# =========================
# Init
# =========================
board = WhisPlayBoard()
board.set_backlight(100)
VIDEO_PATH = "/home/pi/matrix.mp4"
font = ImageFont.truetype(
"/usr/share/fonts/truetype/fonts-japanese-gothic.ttf", 26
)
show_text = False
current_text = ""
# RSS source list (expandable)
RSS_FEEDS = [
"https://www3.nhk.or.jp/rss/news/cat5.xml"
#"https://news.yahoo.co.jp/rss/topics/it.xml"
]
def fetch_news():
headlines = []
for url in RSS_FEEDS:
feed = feedparser.parse(url)
for entry in feed.entries:
headlines.append(entry.title)
return headlines
def get_headlines(n=1):
news = fetch_news()
return news[:n]
# =========================
# Overlay icon
# =========================
def overlay_icon(frame, icon_path, x, y, size=None):
base = Image.fromarray(frame).convert("RGBA")
icon = Image.open(icon_path).convert("RGBA")
if size:
icon = icon.resize(size)
datas = icon.getdata()
new_data = []
for item in datas:
if item[0] > 240 and item[1] > 240 and item[2] > 240:
new_data.append((255, 255, 255, 0))
else:
new_data.append(item)
icon.putdata(new_data)
base.paste(icon, (x, y), icon)
return np.array(base.convert("RGB"))
# =========================
# Button handler
# =========================
def on_button():
global show_text, current_text, mode, speech_ready
if mode == 0:
mode = 1
show_text = False
speech_ready = False
headlines = get_headlines(3)
for text in headlines:
current_text = text
print(text)
speech_ready = True
show_text = True
speak(text)
else:
mode = 0
show_text = False
current_text = ""
board.on_button_press(on_button)
# =========================
# Image processing
# =========================
def zoom_center(frame, zoom=1.2):
h, w, _ = frame.shape
new_w = int(w / zoom)
new_h = int(h / zoom)
x1 = (w - new_w) // 2
y1 = (h - new_h) // 2
cropped = frame[y1:y1+new_h, x1:x1+new_w]
return cv2.resize(cropped, (w, h))
def frame_to_rgb565(frame):
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
r = (frame[:, :, 0] >> 3).astype('uint16')
g = (frame[:, :, 1] >> 2).astype('uint16')
b = (frame[:, :, 2] >> 3).astype('uint16')
rgb565 = (r << 11) | (g << 5) | b
high = (rgb565 >> 8).astype('uint8')
low = (rgb565 & 0xFF).astype('uint8')
return np.dstack((high, low)).flatten().tolist()
def resize_and_crop(frame):
h, w, _ = frame.shape
screen_w = board.LCD_WIDTH
screen_h = board.LCD_HEIGHT
aspect = w / h
screen_aspect = screen_w / screen_h
if aspect > screen_aspect:
new_h = screen_h
new_w = int(new_h * aspect)
frame = cv2.resize(frame, (new_w, new_h))
x = (new_w - screen_w) // 2
frame = frame[:, x:x + screen_w]
else:
new_w = screen_w
new_h = int(new_w / aspect)
frame = cv2.resize(frame, (new_w, new_h))
y = (new_h - screen_h) // 2
frame = frame[y:y + screen_h, :]
return frame
def split_text(text, max_width=18):
lines = []
current = ""
width = 0
for ch in text:
w = 2 if unicodedata.east_asian_width(ch) in "FWA" else 1
if width + w > max_width:
lines.append(current)
current = ch
width = w
else:
current += ch
width += w
if current:
lines.append(current)
return lines
# =========================
# Draw text
# =========================
def draw_text(frame, text, x, y):
pil_img = Image.fromarray(frame)
draw = ImageDraw.Draw(pil_img)
lines = split_text(text, max_width=18)
for i, line in enumerate(lines):
draw.text((x, y + i * 40), line, font=font, fill=(180, 255, 255))
return np.array(pil_img)
# =========================
# Main loop
# =========================
cap = cv2.VideoCapture(VIDEO_PATH)
if not cap.isOpened():
print("Failed to open video")
sys.exit()
try:
while True:
ret, frame = cap.read()
if not ret:
cap.set(cv2.CAP_PROP_POS_FRAMES, 0)
continue
frame = cv2.resize(frame, (160, 120))
frame = resize_and_crop(frame)
frame = zoom_center(frame, 1.5)
if show_text and speech_ready:
frame = overlay_icon(
frame,
"/home/pi/icon_speaker.png",
75,
0
)
frame = draw_text(frame, current_text, 5, 110)
rgb565 = frame_to_rgb565(frame)
board.draw_image(
0, 0,
board.LCD_WIDTH,
board.LCD_HEIGHT,
rgb565
)
time.sleep(0.08)
except KeyboardInterrupt:
pass
finally:
cap.release()
board.cleanup()
ボタンを押すとRSSからニュースを3件取得し、見出しを順番に処理します。取得件数はget_headlines(3)で指定しており、この数値を変更することで取得するニュースの件数を調整できます。取得したテキストはOpen JTalkで音声に変換され、スピーカーから再生されます。表示処理ではOpenCVで動画を再生し、その上にPillowでテキストとアイコンを重ねて描画します。
再度ボタンを押すと表示がリセットされ、ニュースの表示が終了します。その後にもう一度ボタンを押すことで、最新のニュースを再取得できます。つまり、ボタン操作のたびに最新のニュースを取得できる仕様にしました。
ローカル環境でチャットボットを動かす

Raspberry Pi上で音声入力からAIの応答生成、音声出力までを一通り動かすことで、ローカル環境だけで会話できるチャットボットを構築してみました。マイクで入力した音声をテキストに変換し、LLMで応答を生成し、その結果を音声として再生する仕組みです。
今回の構成ではRaspberry Pi 5とAI HAT+2を使用しています。処理性能の関係からRaspberry Pi Zero 2での動作は現実的ではありません。
認識精度や返答内容はまだ高いとは言えず、意図しない変換や不自然な応答になることもありますが、ローカル環境でここまでの処理が実現できる点は大きな魅力です。今後のモデルや音声認識技術の進化によって、より自然な会話ができるようになることが期待されます。
実際の構築手順や設定方法については、以下の記事の後半部分で詳しく解説しています。
»【生成AIに特化】Raspberry Pi AI HAT+ 2レビュー
音声インターフェースが変えるラズパイ活用

以前から音声で操作・応答できるデバイス制作に興味があったものの、なかなかコンパクトなスピーカーが見つからずに二の足を踏んでいました。Whisplay HATはLCD、ボタンまで一体化されており、この1枚で表示と音声の両方を手軽に扱える点が大きな魅力です。
ニュースの取得と音声読み上げを組み合わせることで、実用的なガジェットも無理なく作れました。
今後はエッジAIの進化により、音声インターフェースを活用する場面はさらに増えていくことが予想されます。これまでクラウドに依存していた処理も、ローカルで完結できるケースが増えてきました。Raspberry Piの可能性を広げる一歩として、ぜひ体験してみてはいかがでしょうか。