【PR】この記事には広告が含まれています。

Raspberry Piで生成AIを動かす。これまで何度か試しましたが、短い文章であれば数秒で生成できても、長文になると待ち時間が気になることも。ラズパイで動くこと自体は興味深いものの、実用面では一歩足りない印象がありました。

そんな中で登場したのが、Raspberry Pi 5に取り付けて使うRaspberry Pi AI HAT+ 2です。従来のAI HAT+が画像認識などの推論AIを得意としてきたのに対し、本製品はLLM(大規模言語モデル)やVLM(視覚言語モデル)といった生成AIの実行を主目的に設計されています。
今回、Raspberry Pi Ltdさまより製品の提供をいただき、実機を試用する機会を賜りました。本記事では実際に触ってみて分かった処理時間の感覚や使い勝手を中心に、AI HAT+ 2の可能性に迫ります。
AI HAT+ 2 は Raspberry Pi 5 専用の拡張ボード

近年、クラウドに頼らずデバイス単体でAI処理を行うエッジAIが注目されています。通信遅延やプライバシーの問題を避けられる点から、Raspberry PiにはAI処理を担うプラットフォームとしての期待が高まっています。AI HAT+ 2 は、その流れの中で登場した拡張ボードです。

Hailoは、エッジデバイス向けに高性能かつ低消費電力のAIアクセラレータを開発している半導体メーカーです。
従来の AI HAT+ との違い
| 項目 | AI HAT+ | AI HAT+ 2 |
|---|---|---|
| 搭載チップ | Hailo-8 / Hailo-8L | Hailo-10H |
| 処理性能 | 13 TOPS / 26 TOPS | 40 TOPS |
| 対応機種 | Raspberry Pi 5 | Raspberry Pi 5 |
| 専用オンボードRAM | なし | 8GB 搭載 |
| 価格 | 13 TOPS:$70 26 TOPS:$110 | $130 |
| 販売ページ | 詳細を見る | 詳細を見る |
AI HAT+ 2はRaspberry Pi 5の上部に取り付け、PCIe(PCI Express)で接続して高速にデータ通信を行う拡張ボードです。
AI HAT+ 2は、従来モデルの単なる上位版ではありません。推論AIを高速に処理するための製品から、生成AIを扱うための製品へと役割が分かれたと考えるのが適切です。
従来のAI HAT+ が推論処理でRaspberry Pi本体のメモリを使用するのに対して、AI HAT+ 2は8GBの専用オンボードRAMを搭載しており、AI処理用のメモリが独立しています。そのため、メモリ競合が起きにくく、AI処理そのものが安定して高速に動作します。
Hailo-10H を搭載した AI アクセラレーター

従来の AI HAT+ が採用していた Hailo-8 / 8L は、画像認識などの推論AIを主用途としていました。一方、AI HAT+ 2 のHailo-10H は、より大規模で複雑なAI処理を扱うことを前提に設計されたチップです。AI HAT+ 2 は、このチップの特性を生かすための構成になっています。
AI HAT+ 2の取り付け

今回、Raspberry Pi本体はRaspberry Pi 5を使用しました。
カメラを使用する場合はこの段階で取り付けておきます。僕はRaspberry Pi Camera Module 3を使用しました。Raspberry Pi Active Cooler(別売り)を装着します。AI HAT+ 2は十分な性能を発揮するため、Active Coolerと一緒に使うことが推奨されています。

付属のネジでスペーサーを取り付け、GPIOピン延長用ヘッダをRaspberry PiのGPIOピンに差し込みます。

AI HAT+ 2本体にチップを冷却するためのヒートシンクを取り付けます。

フラットケーブルをRaspberry Pi側のPCIeポートに入れつつ、GPIOピン延長用ヘッダに差し込みます。

スペーサー部分をネジで固定したら取付完了です。
GPIOピンを使用する場合
キットに付属しているスペーサーを使うと、GPIOピンが隠れてしまい、電子パーツをピンに接続できなくなります。

そこで、別売りのM2.5×11mmのスペーサーに交換することで、GPIOピンの先端を外に出せます。
ただし、この方法ではRaspberry PiとAI HAT+ 2の間隔が狭くなり、Active Coolerが基板に接触するおそれがあります。そのため、Active Coolerは取り外して使用する方が無難です。
セットアップ手順

AI HAT+ 2を使う場合、32GBのmicroSDカードでは途中で容量が足りなくなりました。ファイルサイズの大きいモデルを複数ダウンロードしていくため、余裕を持って使うなら64GB以上のmicroSDカードをおすすめします。
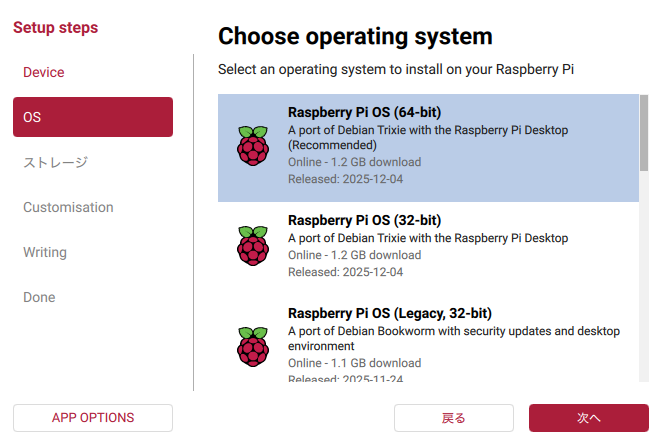
Raspberry Pi OS Trixie を新しくインストールした状態から作業を進めます。別の用途で使っていた環境では、過去の設定などが影響し、AI HAT+ 2 がうまく動作しないことがあるようです。
準備ができたら、Hailo関連のソフトをインストールするための設定を行います。
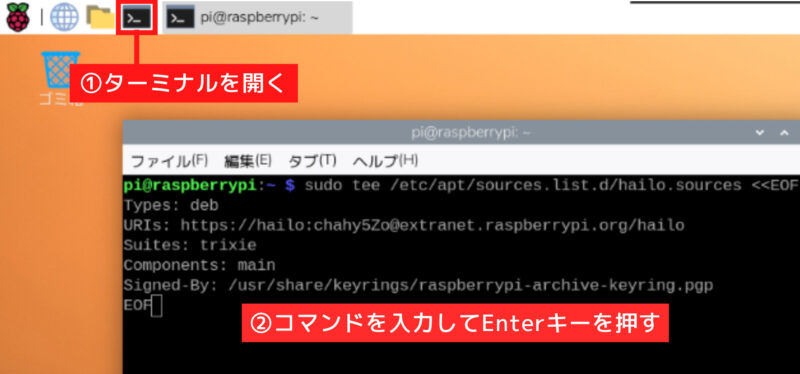
以下のコマンドは途中で分けず、最初から最後までの行を一度に実行します。aptが参照するソフト配布先の一覧にHailo用のパッケージ配布先が追加されます。
sudo tee /etc/apt/sources.list.d/hailo.sources <<EOF
Types: deb
URIs: https://hailo:chahy5Zo@extranet.raspberrypi.org/hailo
Suites: trixie
Components: main
Signed-By: /usr/share/keyrings/raspberrypi-archive-keyring.pgp
EOF
ここで使っているEOFは、「ここまでを書き込む」という区切りを示す目印です。 <<EOF から始まり、最後に書かれた EOFまでの内容が保存されます。
次に、Raspberry Piに登録した内容を反映し、システムを最新の状態に更新します。
sudo apt updateRaspberry Pi ではaptという管理システムを使ってソフトを管理しています。
必要な更新をまとめて適用します。
sudo apt full-upgrade -yRaspberry Piを再起動し、更新内容を反映させます。
sudo rebootDockerのインストール
ブラウザから生成AIを操作するためのWebUI(Webベースの操作画面)を使うには、Dockerのインストールが必須です。WebUIの土台となる Dockerを、Hailoを入れる前に準備しておきます。
Dockerは必要なソフトや設定をまとめて用意し、Raspberry Pi OSの違いに影響されずにプログラムを実行するための仕組みです。
チェックポイント
Raspberry Pi OS TrixieではPython 3.13 が使われていますが、WebUIはこのバージョンに対応していません。そのため、Python環境に依存しないDockerを使ってWebUIを動かします。
まず、環境の競合を防ぐため、すでに入っている Docker 関連パッケージを削除します。
sudo apt remove $(dpkg --get-selections docker.io docker-compose docker-doc podman-docker containerd runc | cut -f1)Dockerを正しくインストールするため、公式リポジトリを追加します。HTTPS通信に必要な証明書と、データ取得用のツール(curl)をインストールします。
sudo apt install ca-certificates curlリポジトリの署名キーを保存するためのディレクトリを作成します。
sudo install -m 0755 -d /etc/apt/keyringsDockerの公式署名キーをダウンロードして保存します。
sudo curl -fsSL https://download.docker.com/linux/debian/gpg -o /etc/apt/keyrings/docker.asc保存した署名キーをシステムから読み取れるように設定します。
sudo chmod a+r /etc/apt/keyrings/docker.ascDocker の配布先を apt に登録します。
sudo tee /etc/apt/sources.list.d/docker.sources <<EOF
Types: deb
URIs: https://download.docker.com/linux/debian
Suites: $(. /etc/os-release && echo "$VERSION_CODENAME")
Components: stable
Signed-By: /etc/apt/keyrings/docker.asc
EOFパッケージ一覧を更新します。
sudo apt updateDocker 本体と関連ツールをインストールします。
sudo apt install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-pluginDocker を起動します。
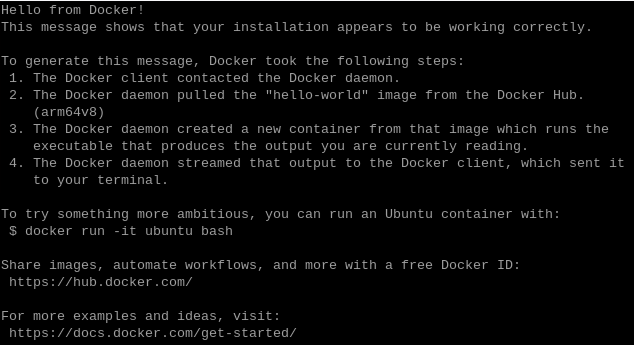
sudo systemctl start dockerDocker が正しく動作するかを確認します。
sudo docker run hello-world「Hello from Docker!」を含むメッセージが表示されれば、Dockerのセットアップは完了です。
Hailo-10Hドライバとランタイムの導入
Hailo-10HをOSから利用できるようにします。ドライバを自動で再構築する仕組み(DKMS)を導入します。
sudo apt install dkmsHailo-10H を使用するためのドライバとランタイム一式をインストールします。
sudo apt install -y hailo-h10-allこの処理は7分かかりました。
再起動します。
sudo rebootHailo Gen-AI Model Zooのインストール
Hailoが提供するGen-AI Model Zooを導入します。Gen-AI Model ZooはCLIやREST APIから利用できる、事前学習済みの生成AIモデルを集めたライブラリです。
この手順は内容が更新される可能性があるため、公式の手順に従ってインストールします。2026年1月11日時点では以下のコマンドを1行づつ実行してインストールしました。
sudo apt install -y libssl-dev
git clone https://github.com/hailo-ai/hailo_model_zoo_genai.git
cd /home/pi/hailo_model_zoo_genai
mkdir build && cd build
cmake -DCMAKE_BUILD_TYPE=Release ..
cmake --build .
mkdir -p ~/.local/bin
cp ./src/apps/server/hailo-ollama ~/.local/bin/
mkdir -p ~/.config/hailo-ollama/
cp ../config/hailo-ollama.json ~/.config/hailo-ollama/
mkdir -p ~/.local/share/hailo-ollama
cp -r ../models/ ~/.local/share/hailo-ollama
echo 'export PATH="$HOME/.local/bin:$PATH"' >> ~/.bashrc
source ~/.bashrchailo-ollamaサーバーの起動
LLMのリクエストを受け付けるサーバーを起動します。hailo-ollamaは、Hailo-10H上でLLMやVLMを動かすためのサーバープログラムです。
hailo-ollamaチェックポイント
私の場合、ここでhailo-ollamaを実行した際にコマンドが見つからないと表示されました。hailo-ollama 本体を ~/.local/bin に配置していましたが、そのパスが反映されていなかったため、コマンドとして認識されなかったためです。
解決方法として、「echo ‘export PATH=”$HOME/.local/bin:$PATH”‘ >> ~/.bashrc」を実行して、 PATH を追加したあと、「source ~/.bashrc」を実行して設定を読み込み直すことで、hailo-ollama を実行できるようになりました。
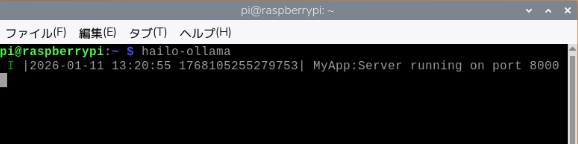
新しいターミナルを開き、次を実行します。使用可能な LLMモデルの一覧が表示されます。
curl --silent http://localhost:8000/hailo/v1/list上記で表示された使用可能なモデルを以下にまとめました。
| モデル名 | 特徴 | 用途 | 開発元 |
| DeepSeek-R1:1.5B | 大規模モデルの思考パターンを小型に凝縮したモデル | 推論・汎用生成 | DeepSeek |
| Llama3.2:1b | シンプルで軽量、基本的な文章生成向け | 一般生成・会話 | Meta |
| qwen2.5-coder:1.5b | コード生成や解析に強い専門モデル | コード生成 | Alibaba Cloud |
| qwen2.5:1.5b | Qwen2.5の基本版、小〜中規模の生成タスク向け | 汎用言語生成・会話 | Alibaba Cloud |
| qwen2:1.5b | Qwenシリーズの前世代で、バランスの取れた生成能力 | 一般生成・会話 | Alibaba Cloud |
私が実際に使ってみたところ、qwen2:1.5bモデルが日本語のやり取りにおいて最も安定しており、回答精度が高いと感じました。他のモデルでは、日本語で質問しても英語で返ってきたり、不自然な日本語になったりすることが多いです。
LLMを動かしてみる
Qwen2 1.5Bモデルをダウンロードします。モデル名は先ほど表示された一覧にあるものへ変更できます。
curl --silent http://localhost:8000/api/pull \
-H 'Content-Type: application/json' \
-d '{ "model": "qwen2:1.5b", "stream" : true }'ダウンロードは10分程度かかります。
以下のコマンドを実行すると、LLMに直接質問できます。
curl --silent http://localhost:8000/api/chat \
-H 'Content-Type: application/json' \
-d '{"model": "qwen2:1.5b", "messages": [{"role": "user", "content": "Translate to French: The cat is on the table."}]}'エラーが出ずに結果が返ってくれば、LLMの実行は成功です。
WebUI(ChatGPT風UI)で動かす
WebUIのDockerイメージを取得します。以下のコマンドでChatGPTのような画面を表示するためのプログラム一式をインターネットから取得します。
sudo docker pull ghcr.io/open-webui/open-webui:mainこのダウンロードも10分以上かかります。
WebUIコンテナを起動します。
sudo docker run -d \
-e OLLAMA_BASE_URL=http://127.0.0.1:8000 \
-v open-webui:/app/backend/data \
--name open-webui \
--network=host \
--restart always \
ghcr.io/open-webui/open-webui:mainチェックポイント
このコマンドを実行する前に、別のターミナルでhailo-ollamaが起動していることを確認してください。
初回起動は数分かかります。次のコマンドで起動状況を確認できます。
sudo docker logs open-webui -f起動完了したら、Raspberry Piのブラウザで次のURLを開きます。
http://127.0.0.1:8080
ChatGPTのような画面が表示されます。
「はじめる」をクリックします。
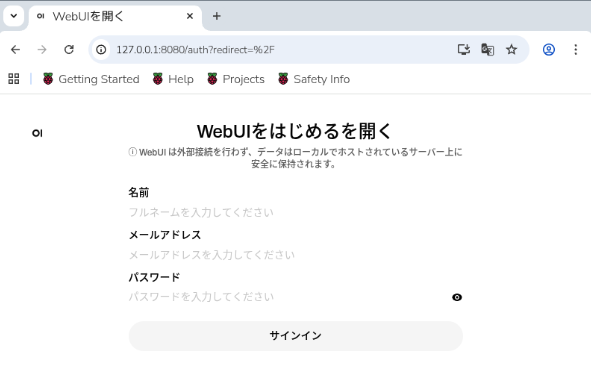
WebUIの初回起動時には、ローカルで使用するユーザー情報の登録が必要です。これは外部サービスへのサインインではなく、Raspberry Pi上でWebUIを管理するための設定です。
登録した情報はRaspberry Pi本体内に保存され、以後はそのユーザーでログインします。
ログインすると、ChatGPTで馴染みのある画面が登場しました。
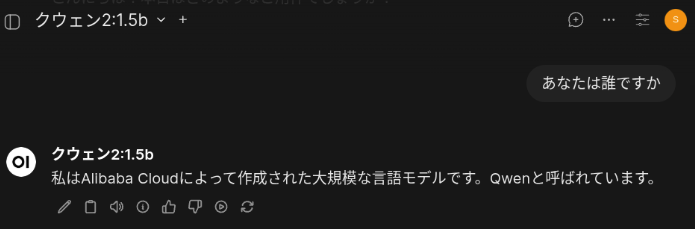
「あなたは誰ですか」の質問に回答してくれました。回答完了までの時間は7秒でした。
ブログに掲載するスクリーンショットでは、明るい画面のままだと文字やUIが見にくいため、ダークモードに切り替えました。
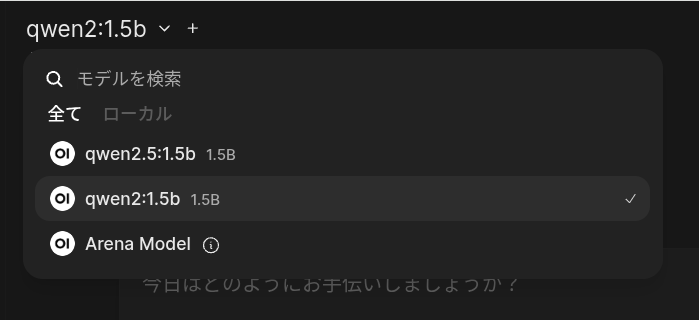
「Qwen2 1.5B」以外のモデルを使用したい場合は、以下の手順でダウンロードします。
qwen2.5:1.5bをWebUIで使えるようにする手順
①ターミナルを開き、hailo-ollamaを実行。
②別のターミナルで、次を実行。curl --silent http://localhost:8000/api/pull -H 'Content-Type: application/json' -d '{ "model": "qwen2.5:1.5b", "stream": true }'
③sudo docker start open-webuiを実行
④ブラウザでhttp://127.0.0.1:8080にアクセスし、モデル一覧からqwen2.5:1.5bを選択
Raspberry Piの再起動後など、次回以降は以下の手順でWebUIを立ち上げます。
再起動後の実行手順
①再起動後はターミナルを2つ開き、1つ目でhailo-ollamaを実行してLLMサーバーを起動。
②もう1つのターミナルでsudo docker start open-webuiを実行。
③ブラウザでhttp://127.0.0.1:8080にアクセスすればWebUIを利用できます。
PythonからLLMを動かす
ローカルLLMは、Pythonから制御することで電子工作やアプリに組み込みやすくなります。ここでは、PythonからローカルLLMを動かすための基本的な流れを説明します。
PythonからローカルLLMを使う前に、ターミナルからhailo-ollamaを実行しておく必要があります。
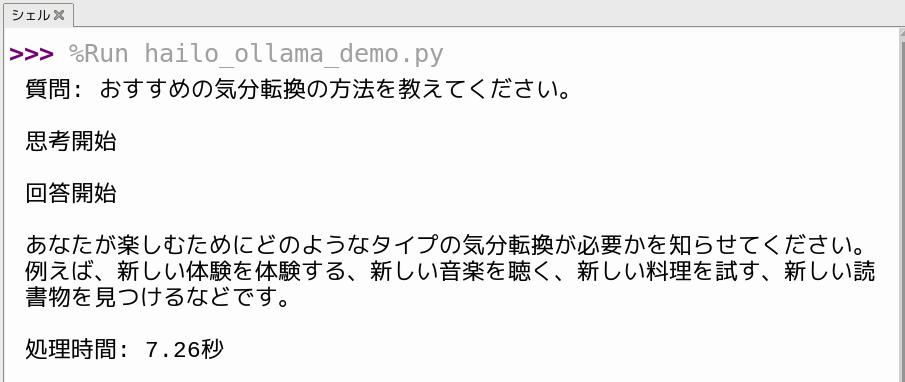
以下のコードはPythonからローカルLLMを呼び出し、回答を生成途中から受け取りつつ最終結果もまとめて取得するためのコードです。
import requests
import json
import time
# ローカルで起動しているLLMのAPIエンドポイント
url = "http://localhost:8000/api/chat"
# ユーザーの質問
question = "おすすめの気分転換の方法を教えてください。"
payload = {
# 使用するLLMモデルを指定
"model": "qwen2:1.5b",
# "model": "qwen2.5:1.5b",
# "model": "llama3.2:1b",
# "model": "deepseek_r1:1.5b",
# LLMに送る会話内容を指定
"messages": [
{"role": "user", "content": question}
]
}
# 質問内容を表示
print(f"質問: {question}\n")
# 思考開始時刻を記録
think_start_time = time.time()
print("思考開始\n")
# LLM APIにPOSTリクエストを送信(ストリーミング)
res = requests.post(url, json=payload, stream=True)
answer_started = False # 回答開始検知フラグ
final_answer = "" # 回答全文を格納する変数
for line in res.iter_lines():
if not line:
continue
data = json.loads(line.decode("utf-8"))
content = data.get("message", {}).get("content", "")
# 回答が初めて返ってきた瞬間
if content and not answer_started:
print("回答開始\n")
answer_started = True
# 回答内容を逐次表示しつつ、変数に蓄積
if content:
print(content, end="", flush=True)
final_answer += content
# 回答終了を検知
if data.get("done"):
elapsed = time.time() - think_start_time
print(f"\n\n処理時間: {elapsed:.2f}秒")
break
13~16行目で使用するLLMモデルを変更できますが、Raspberry Piにダウンロードしたモデルのみ利用できます。
ローカルLLMに質問を送信し、返ってくる文章をその場で表示しながら、同時に後続処理用として1つの変数に保存する構成になっています。
VLMで画像を説明してもらう

VLMを使うと、画像をもとに状況や特徴を言葉で表現させることができます。保存した写真だけでなくカメラ映像もそのまま渡せるため、精度次第ではリアルタイムの状況に応じた判断や提案にも使えそうです。実際に試しながら、回答の精度や処理にかかる時間を確認していきます。
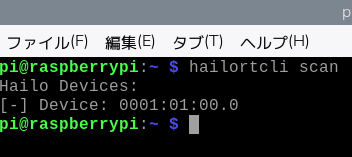
Hailoデバイスが認識されていることを確認する。
hailortcli scan以下のようにデバイスアドレスが表示されれば、Hailoデバイスは正しく認識されています。
hailo-apps リポジトリを取得します。
git clone https://github.com/hailo-ai/hailo-apps.githailo-appsディレクトリに移動
cd hailo-appsvenvという名前のPython仮想環境を作成します。
python3 -m venv venv --system-site-packages仮想環境を有効化します。
source venv/bin/activatePortAudioをOS側にインストールします。これをしないと、PyAudioのビルドでエラーが出てしまいます。
sudo apt update
sudo apt install -y portaudio19-devhailo-appsが定義しているGenAI用の追加依存関係をまとめてインストールします。
pip install -e ".[gen-ai]"モデルのダウンロードや保存時に権限エラーが発生するのを防ぐため、事前にディレクトリを作成し、所有者をpiに変更します。まず、/usr/local/hailoディレクトリを作成します。
sudo mkdir -p /usr/local/hailo以下を実行して、/usr/local/hailo以下のファイルとディレクトリの所有者をユーザーpiとグループpiに変更します。
sudo chown -R pi:pi /usr/local/hailo保存した画像を説明させる
simple_vlm_chat を実行します。初回実行時はVLMモデル(Qwen2-VL-2B-Instruct for hailo10h)のダウンロードが行われるため、時間がかかります。
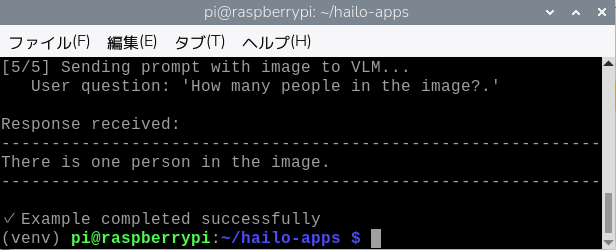
python -m hailo_apps.python.gen_ai_apps.simple_vlm_chat.simple_vlm_chatこのコマンドは、リポジトリ内の doc/images/barcode-example.png という画像を使って、HailoのVision Language Modelを試すデモを実行します。

この画像に対して “How many people in the image?”(この画像には何人の人が写っていますか?) という質問を行います。
「There is one person in the image.(この画像には1人の人物が写っています)」
と回答されました。
VLMモデルには Alibaba Cloud開発のQwen2-VL-2B-Instructが使われており、これが Hailo-10H 向けに最適化された形で提供されています。
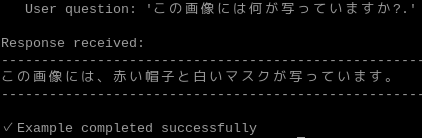
「/home/pi/hailo-apps/hailo_apps/python/gen_ai_apps/simple_vlm_chat/simple_vlm_chat.py」のコードの一部を変更することで、渡す画像や質問の変更ができます。

質問を日本語に変えてみました。ざっくりとした回答ですが、赤い帽子と白いマスクが認識されており、悪くない結果です。
カメラの映像を説明させる

以下を実行すると、Raspberry Piカメラの映像についてVLMに質問できます。
python -m hailo_apps.python.gen_ai_apps.vlm_chat.vlm_chat --input rpiRaspberry Piカメラが起動し、ライブ映像が画面に表示されます。
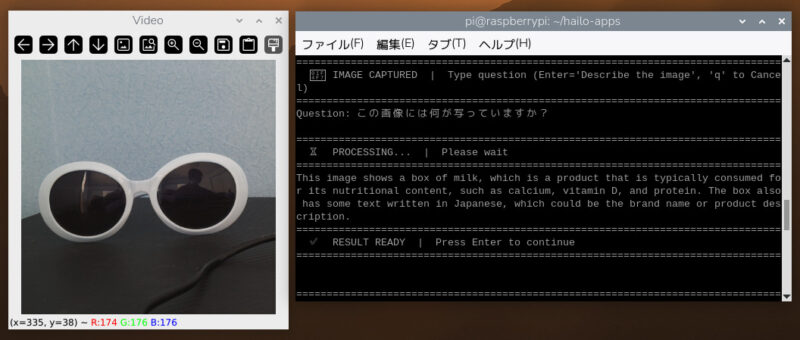
Enterキーを押すと、その時点の映像が静止画として取得されます。静止した画像に対してターミナル上で質問を入力すると、VLMが画像を解析して回答を返します。
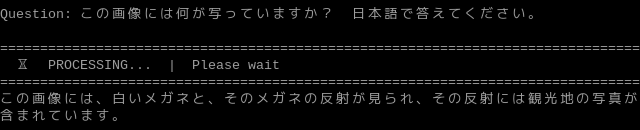
応答が始まるまでにかかる時間は約2秒で、その速さに驚きました。「日本語で答えてください」を質問に含めると日本語で回答が返ってきます。
プログラムをそのまま実行すると、カメラ映像中のオレンジ色の部分が青色に変換されてしまう不具合があったため、「/home/pi/hailo-apps/hailo_apps/python/gen_ai_apps/vlm_chat/vlm_chat.py」の105行目をコメントアウト(行の先頭に#をつけて無効化)し、その下の行に「get_frame = lambda: picam2.capture_array()」を追加しました。
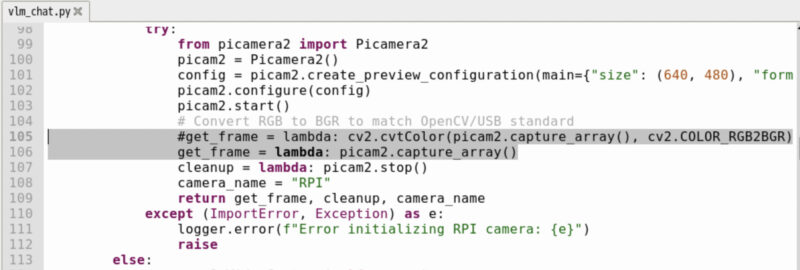
不要な色の変換処理を無効にし、カメラで取得した画像をそのまま使うように変更することで、正しい色で表示されるようになりました。
Raspberry Pi再起動後の実行手順
「cd hailo-apps」でディレクトリに移動
「source venv/bin/activate」でPythonの仮想環境を有効化
Pythonスクリプトを実行
今回使用したVLMでは、日本語で質問した場合に誤った物体名を返すことがあり、ミカンの映像を「にんにく」と回答する例が見られました。一方、同じ画像に対して英語で質問すると、「orange」と正しく認識され、英語で回答させた方が精度が高いようです。
PythonからVLMを動かす
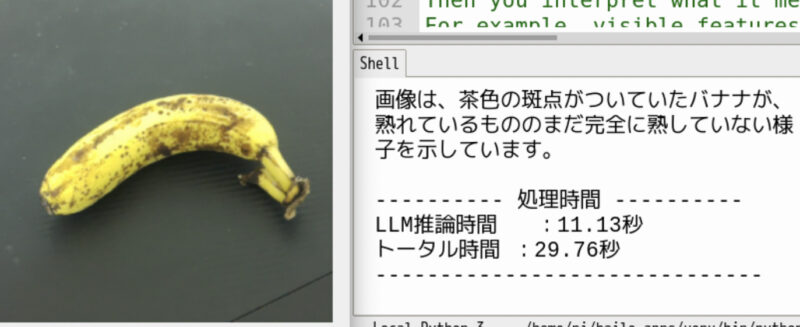
以下はカメラで取得した画像をHailoのVLMで解析し、内容をテキストとして生成するPythonプログラムです。日本語で回答させると精度が悪いので、英語のVLM回答をローカルLLMのQwen2:1.5bで日本語に翻訳する処理も行います。
Qwen2:1.5bをダウンロードして、フォルダに配置する方法はLLMを「Qwen2 1.5B」に変更するで解説しています。
以下はカメラで取得した映像をHailoで解析して内容を英語で説明し、その結果を日本語に翻訳して表示するプログラムです。
import subprocess
import time
# エラー回避のための強制開放(前回プロセスの残骸対策)
subprocess.run(
"sudo fuser -k /dev/video* /dev/media* /dev/v4l-subdev*",
shell=True,
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL
)
time.sleep(1)
import sys
import time
import signal
import os
import cv2
from typing import Optional
from hailo_apps.python.gen_ai_apps.vlm_chat.backend import Backend
from hailo_apps.python.core.common.core import (
get_standalone_parser,
handle_list_models_flag,
resolve_hef_path,
)
from hailo_apps.python.core.common.defines import (
VLM_CHAT_APP,
HAILO10H_ARCH,
)
from hailo_platform import VDevice
from hailo_platform.genai import LLM
def translate_to_japanese(text: str) -> str:
vdevice_llm = VDevice()
llm = LLM(vdevice_llm, "/home/pi/models/Qwen2-1.5B-Instruct.hef")
prompt = f"以下の英文を自然で正しい日本語の表現で翻訳してください。難しい漢字を使わないこと\n\n{text}"
#print(prompt)
messages = [
{"role": "user", "content": prompt}
]
result = ""
for chunk in llm.generate(messages):
result += chunk
llm.release()
return result.replace("<|im_end|>", "").strip()
# =========================
# 設定
# =========================
WAIT_SECONDS = 3 # 撮影までの待機時間
QUESTION = """
Look at the camera image carefully.
Describe what is happening in the image.
Be concise and clear.
Mention the main subject and important details.
"""
MAX_TOKENS = 30
TEMPERATURE = 0.1
SEED = 42
# 画像説明用のシステムプロンプト
SYSTEM_PROMPT = """
You see images from a camera.
You describe the image clearly and objectively.
Focus on what is visible.
"""
INFERENCE_TIMEOUT = 60
WINDOW_NAME = "Captured Frame"
def extract_model_name(hef_path: str) -> str:
# hefファイル名からモデル名を取得
return os.path.splitext(os.path.basename(hef_path))[0]
class OneShotVLMApp:
def __init__(self, hef_path: str):
self.hef_path = hef_path
self.backend: Optional[Backend] = None
self.running = True
signal.signal(signal.SIGINT, self._signal_handler)
def _signal_handler(self, sig, frame):
self.running = False
def _init_camera(self):
from picamera2 import Picamera2
from libcamera import controls
picam2 = Picamera2()
config = picam2.create_preview_configuration(
main={"size": (320, 240), "format": "RGB888"}
)
picam2.configure(config)
picam2.start()
# オートフォーカス設定
picam2.set_controls({
"AfMode": controls.AfModeEnum.Continuous,
"AfSpeed": controls.AfSpeedEnum.Fast,
})
return picam2
def _init_backend(self):
# Hailo VLMバックエンド初期化
self.backend = Backend(
hef_path=self.hef_path,
max_tokens=MAX_TOKENS,
temperature=TEMPERATURE,
seed=SEED,
system_prompt=SYSTEM_PROMPT,
)
def run(self):
picam2 = self._init_camera()
self._init_backend()
cv2.namedWindow(WINDOW_NAME, cv2.WINDOW_AUTOSIZE)
# ---------- ライブ表示 ----------
while self.running:
start_time = time.time()
captured_frame = None
while self.running and captured_frame is None:
frame = picam2.capture_array()
rgb_frame = Backend.convert_resize_image(frame)
bgr_frame = cv2.cvtColor(rgb_frame, cv2.COLOR_RGB2BGR)
cv2.imshow(WINDOW_NAME, bgr_frame)
# 指定時間経過で撮影
if (time.time() - start_time) >= WAIT_SECONDS:
captured_frame = cv2.cvtColor(rgb_frame, cv2.COLOR_RGB2BGR)
break
if cv2.waitKey(1) & 0xFF == ord("q"):
self.running = False
break
if not self.running:
break
loop_start = time.perf_counter()
t0 = time.perf_counter()
# VLM推論を実行(画像→テキスト生成)
result = self.backend.vlm_inference(
captured_frame,
QUESTION,
INFERENCE_TIMEOUT,
)
t1 = time.perf_counter()
inference_time = t1 - t0
answer_text = result.get("answer", "回答を取得できませんでした")
model_name = extract_model_name(self.hef_path)
print("\n=====================================\n")
print("---------- 実行情報 ----------")
print(f"モデル名 :{model_name}")
print(f"VLM推論時間 :{inference_time:.2f}秒")
print("------------------------------\n")
# Hailoデバイス解放
self.backend.close()
# 翻訳 -----------------------------------------------
t2 = time.perf_counter()
translated_text = translate_to_japanese(answer_text)
print(translated_text)
t3 = time.perf_counter()
llm_time = t3 - t2
total_time = time.perf_counter() - loop_start # トータル時間計算
print("\n---------- 処理時間 ----------")
print(f"LLM推論時間 :{llm_time:.2f}秒")
print(f"トータル時間 :{total_time:.2f}秒")
print("------------------------------\n")
self._init_backend()
time.sleep(1)
if cv2.waitKey(30) & 0xFF == ord("q"):
break
if __name__ == "__main__":
parser = get_standalone_parser()
handle_list_models_flag(parser, VLM_CHAT_APP)
options = parser.parse_args()
hef_path = resolve_hef_path(
options.hef_path if hasattr(options, "hef_path") else None,
app_name=VLM_CHAT_APP,
arch=HAILO10H_ARCH,
)
if hef_path is None:
sys.exit(1)
OneShotVLMApp(str(hef_path)).run()
sys.exit(0)
VLMからLLMへ処理を切り替える際に、プロセスの起動やメモリ確保、モデルのロードが行われるため時間がかかります。結果、VLMの推論自体は速くても、全体の処理時間は長くなります。
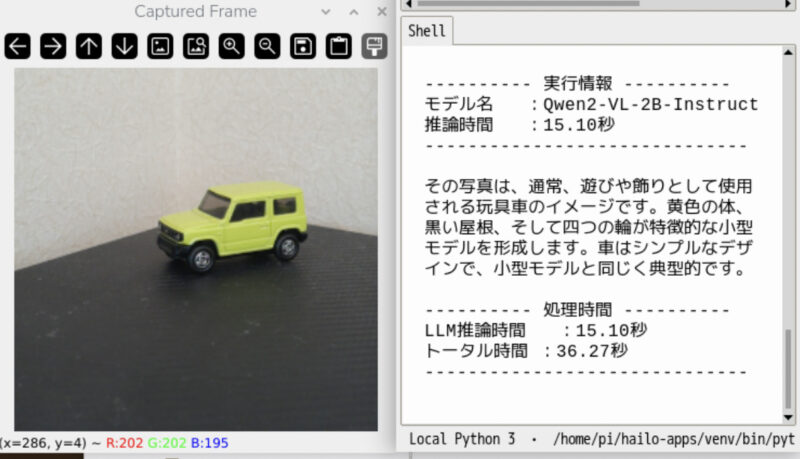
VLM作例紹介

ローカルVLMを使って、カメラに映った物や人物をひたすら褒めてくれる装置を作りました。使用したのはTouch Display 2の5インチモデルです。カメラを固定できるスタンドは、3Dプリンターで自作しました。

背景で流れている映画マトリックス風の動画は、Pixabayで公開されているものを使用しました。これがあるだけで、近未来感が増します。

英語のVLM回答をローカルLLMで日本語に翻訳させているので、英文と日本語文が交互に流れます。日本語回答までの処理時間は合計で30秒くらいです。
繰り返し動かしても、API利用料金を気にせずに済むところが良いですね。
テキストをしゃべらせる

音声合成(TTS)はRaspberry PiのCPUで動作します。PiperはONNX Runtimeという仕組みで動いており、これはCPUやGPU向けに作られているため、Hailo(Raspberry Pi AI HAT+ 2)では動かないようです。
音声を出力させるためにスピーカーが必要です。今回はPiSugar Whisplay Hatを使用します。コンパクトですが、スピーカーとマイクが搭載されています。
以下を1行ずつ実行すると、Whisplay HATのスピーカーとマイクが使える状態になります。
git clone https://github.com/PiSugar/Whisplay.git --depth 1
cd Whisplay/Driver
sudo bash install_wm8960_drive.sh
sudo rebootPiperで音声を再生する
音声合成エンジンであるPiperのTTSモデルをダウンロードします。
hailo-audio-troubleshoot --install-tts以下を実行すると、「Hello, how are you today?」というテキストが音声に変換され、スピーカーから再生されます。
python -c "from hailo_apps.python.gen_ai_apps.gen_ai_utils.voice_processing.text_to_speech import TextToSpeechProcessor as T; t=T(); t.queue_text('Hello, how are you today?'); t.wait_for_completion()"OpenJTalkで日本語音声を再生する
Piperでは日本語対応しているモデルを使用できないようです。そこで、OpenJTalkをインストールすることにしました。
sudo apt install -y open-jtalk open-jtalk-mecab-naist-jdic hts-voice-nitech-jp-atr503-m001OpenJTalkは、名古屋工業大学を中心に開発された、日本語の文章を音声に変換して読み上げるオープンソースの音声合成エンジンです。
OpenJTalkで日本語を音声合成するための辞書と音声モデルをインストールします。
sudo apt install -y open-jtalk-mecab-naist-jdic hts-voice-nitech-jp-atr503-m001以下で日本語がしゃべれます。「こんにちは」というテキストを音声に変換してWAVファイルに保存し、その音声を再生しています。
echo "こんにちは" | open_jtalk -x /var/lib/mecab/dic/open-jtalk/naist-jdic -m /usr/share/hts-voice/nitech-jp-atr503-m001/nitech_jp_atr503_m001.htsvoice -ow /tmp/test.wav && aplay /tmp/test.wav女性の声のモデルもインストールしてみます。
wget https://downloads.sourceforge.net/project/mmdagent/MMDAgent_Example/MMDAgent_Example-1.8/MMDAgent_Example-1.8.zipZIP形式のファイル「MMDAgent_Example-1.8.zip」を解凍します。
unzip MMDAgent_Example-1.8.zipmeiフォルダをシステムの音声データ用ディレクトリ(/usr/share/hts-voice/)にコピーします。
sudo cp -r MMDAgent_Example-1.8/Voice/mei /usr/share/hts-voice/Pythonからは以下のように再生します。
import subprocess
def speak_japanese(text, voice="normal", speed=0.8):
# voiceで選択できる種類
# "normal" : 標準
# "happy" : 明るい
# "angry" : 怒り
# "sad" : 悲しい
# "bashful" : 照れ
voice_path = f"/usr/share/hts-voice/mei/mei_{voice}.htsvoice"
subprocess.run(
[
"open_jtalk",
"-x", "/var/lib/mecab/dic/open-jtalk/naist-jdic",
"-m", voice_path,
"-r", str(speed),
"-ow", "/tmp/test.wav"
],
input=text,
text=True
)
subprocess.run(["aplay", "/tmp/test.wav"])
speak_japanese("こんにちは", "happy")日本語テキストをOpenJTalkで音声に変換し、/tmp/test.wavに保存してから再生する処理です。読み上げる内容はtextに入れた文字で決まり、voiceで声の種類(normal・happyなど)を選べます。speedで話す速さを調整でき、数値が小さいほどゆっくり、大きいほど速くなります。
最後のspeak_japanese("こんにちは", "happy")は、「こんにちは」を明るい声で再生する指定です。
AIと音声で会話する
hailo-appsのvoice_assistant.pyを使うことで、マイク入力から音声認識・LLM処理・音声出力まで一連の流れを実行できます。
引き続き、PiSugar Whisplay Hatをスピーカー・マイクとして使用します。
hailo-appsディレクトリに移動し、仮想環境venvを有効化。
cd hailo-apps && source venv/bin/activatevoice_assistant.pyを起動します。初回実行時は音声認識モデルのダウンロードが行われるため、10分程度かかります。
python -m hailo_apps.python.gen_ai_apps.voice_assistant.voice_assistant-mは指定したモジュールをパッケージとして実行するためのオプションです。
起動すると待機状態になり、SPACEキーを押すと録音が始まります。話し終わったらもう一度SPACEキーを押すと録音が止まり、その内容がテキストに変換されてAIの応答が表示・音声再生されます。会話の履歴をリセットしたいときはCキー、アプリを終了したいときはQキーを押します。
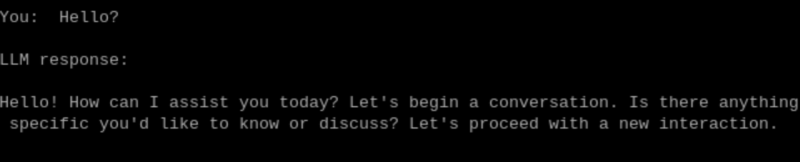
デフォルトの構成では日本語で会話できないので、以下に変更します。
マイク → 音声認識(日本語) → LLM(qwen2:1.5b) → TTS(open_jtalk)
日本語の音声を認識できるようにする
音声認識を日本語で動作させるための設定を追加します。
/home/pi/hailo-apps/hailo_apps/python/gen_ai_apps/voice_assistant/voice_assistant.pyを開いて、language=”ja”を追加します。
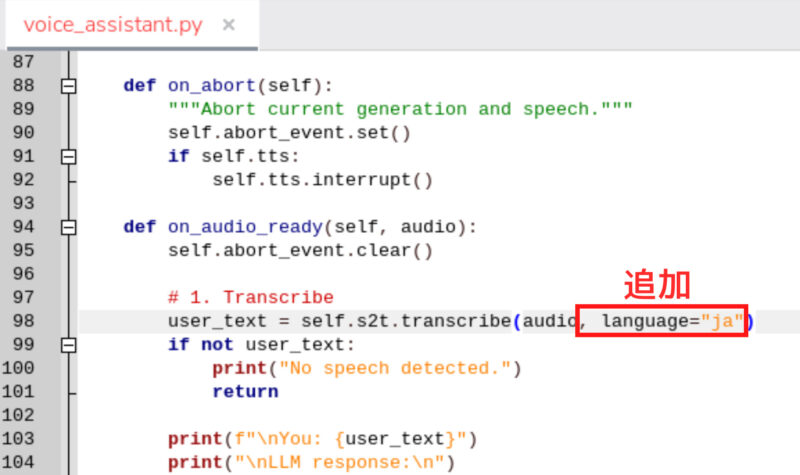
これにより、音声入力が日本語として処理されるようになります。認識精度は決して高くはありませんが、処理の速さには驚きました。
LLMを「Qwen2 1.5B」に変更する
認識した音声を回答させる際にデフォルトのモデルでは回答が安定しません。そこで、比較的日本語に強いqwen2:1.5bモデルを使用します。
https://hailo.ai/products/hailo-software/model-explorer/generative-ai/qwen2-1-5b/のページ下部からCompiled Modelをダウンロードします。ファイルサイズが大きいため、かなり時間がかかります。
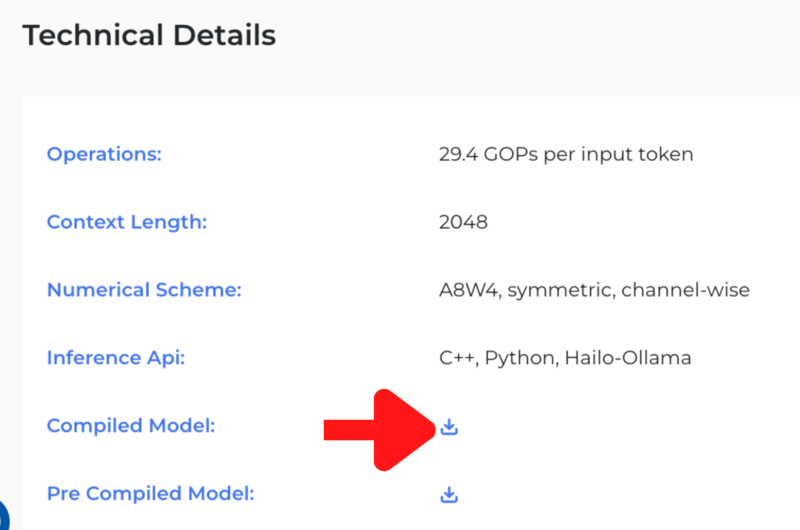
モデルを保存するフォルダを作成
mkdir -p /home/pi/modelsダウンロードしたモデルを移動
mv /home/pi/ダウンロード/Qwen2-1.5B-Instruct.hef /home/pi/models//home/pi/hailo-apps/hailo_apps/python/gen_ai_apps/voice_assistant/voice_assistant.pyを開いて、モデルのパスを変更します。
以下の行にmodel_path = “/home/pi/models/Qwen2-1.5B-Instruct.hef”を追加します。
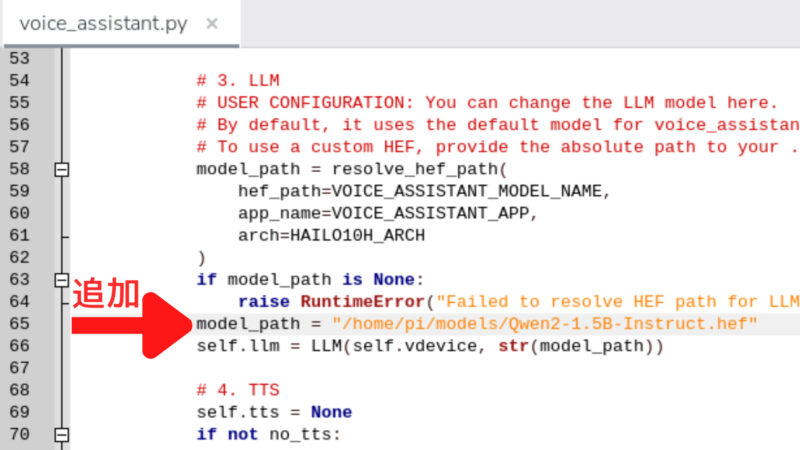
日本語で回答してもらうために、import文の下に以下を追加します。from hailo_apps.python.core.common.defines import LLM_PROMPT_PREFIX, SHARED_VDEVICE_GROUP_ID, HAILO10H_ARCH, VOICE_ASSISTANT_APP, VOICE_ASSISTANT_MODEL_NAMEの行より下に記述します。
LLM_PROMPT_PREFIX = "日本語で答えてください。\n"TTSを日本語対応させる
先ほどインストールしたOpenJTalkを使用するために日本語TTS用ファイルを作成します。
nano ~/hailo-apps/hailo_apps/python/gen_ai_apps/voice_assistant/tts_openjtalk.pytts_openjtalk.pyに、以下のコードを保存します。
import subprocess
def speak_japanese(text, voice="normal", speed=0.8):
voice_path = f"/usr/share/hts-voice/mei/mei_{voice}.htsvoice"
subprocess.run(
[
"open_jtalk",
"-x", "/var/lib/mecab/dic/open-jtalk/naist-jdic",
"-m", voice_path,
"-r", str(speed),
"-ow", "/tmp/test.wav"
],
input=text,
text=True
)
subprocess.run(
["aplay", "/tmp/test.wav"],
stdout=subprocess.DEVNULL,
stderr=subprocess.DEVNULL
)voice_assistant.pyの先頭付近に以下を追加
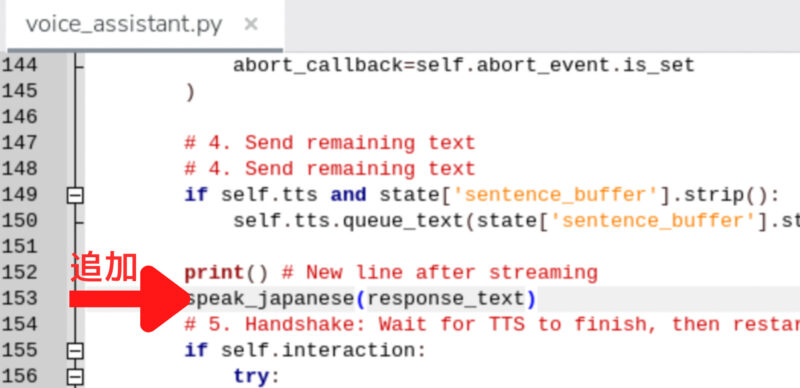
from .tts_openjtalk import speak_japanesespeak_japanese(response_text)を追加
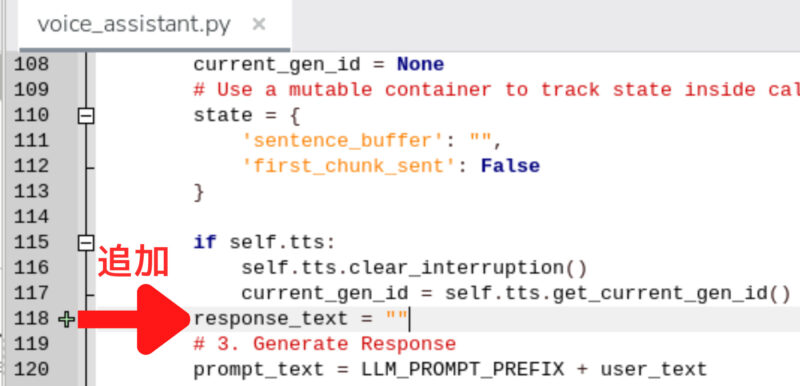
response_text = “”を追加
以下を追加
def collect_callback(chunk: str):
nonlocal response_text
response_text += chunk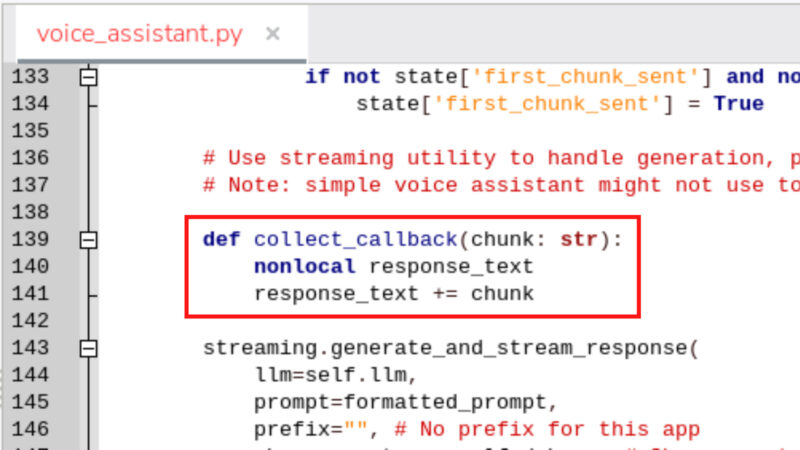
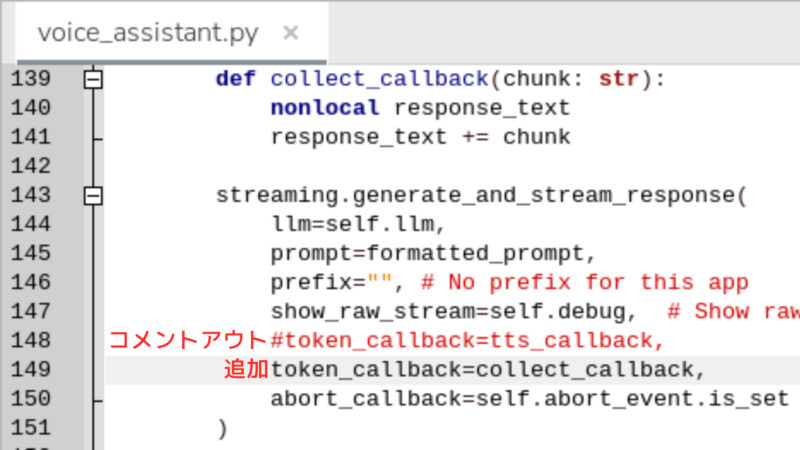
”token_callback=tts_callback”を”token_callback=collect_callback”に変更
voice_assistant.pyを以下のコマンドで実行します。
python -m hailo_apps.python.gen_ai_apps.voice_assistant.voice_assistant --no-tts日本語の音声を認識し、日本語で返答を生成し、そのまま音声として再生できるようになりました。
一連の流れがすべてRaspberry Pi上で動作しており、実際に声でやり取りできる体験はとても新鮮です。
認識精度や返答内容については、意図しない変換や不自然な応答になることもあります。それでも、この速度で会話のようなやり取りが成立するのは、触っていて面白さを感じられるレベルです。
現時点では英語と比べて日本語の精度が低い傾向があり、初期のChatGPTと似た印象を受けます。今後のモデルや音声認識の進化によって、より自然で正確な会話ができるようになることが期待されます。
まとめ

Raspberry Pi AI HAT+ 2を使ってみると、Raspberry Pi上でもLLMの回答が数秒で返ってくることがわかり、エッジAIとしての可能性にワクワクしました。カメラを使った生成AIでは、さまざまなシチュエーションや質問を次々に試してみたくなるような楽しさがあります。API利用料金を気にせず実行できるため、プロンプトや処理の調整を気軽に繰り返せる点も大きな利点です。
一方で、日本語の回答精度が安定しない場面があり、現時点では用途を選びながら使う必要があると感じました。ただ、この点はAI HAT+ 2自体の問題ではなく、モデルやソフトウェアの進化によって改善される余地があり、今後に期待したい部分です。
生成AIを単体で使うだけでなく、電子工作やセンサー、カメラと組み合わせることで、Raspberry Piならではの使い方に広げられそうです。実際にいろいろ試してみて、面白い形になったものがあれば、この記事に追記していきます。
ありがとうございます!
おかげさまで無事に動かすことができました。
ところで、もしかして
「Hailo Gen-AI Model Zooのインストール」のところで、
6行目と7行目の間に
mkdir -p ~/.local/bin
が抜けていないでしょうか。
ご指摘ありがとうございます。
環境によっては~/.local/binが存在せず、手順どおりに実行するとエラーになる可能性があります。
ご指摘を踏まえ、mkdir -p ~/.local/binを追加する形で記事を修正しました。
ありがとうございました。